Monitor servers through plug-in scripts.
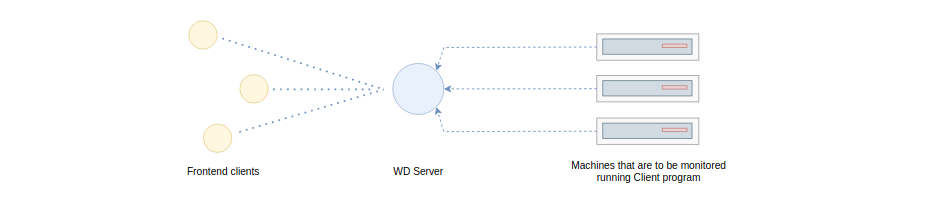
WD has mainly two components - the client and server. Client is a program that runs all on the machines we have to monitor and Server is a program that runs on a single (alert) server that listens for incoming alerts sent by the Clients upon any issue on the machines they run on.
The server (is a combination of gRPC server and a WebSocket server that) listens for incoming alerts from Clients and broadcasts the same to listening connections.
Usage of server:
-grpc-addr string
network address addr on which gRPC server should listen on (default ":40090")
-http-addr string
network address addr on which http server should listen on (default ":40080")
-l string
log directory (default "log")
It, by default, listens on ports 40090 and 40080 for gRPC and WebSocket connections respectively, and uses ./log/ directory for logging. All those can be tuned using the flags given above. Note: It is restricted to handle only up to 1000 WebSocket connections.
Logs are split on a daily basis and stored to the logging directory mentioned via -l with name in the format yyyy-month-dd.
Client is a binary that should run on all the machines which are to be monitored. All Clients should have a configuration file inside which we have to explicitly mention the list of tasks or checks that are to be performed. Whenever a task fails, it will trigger an alert, which will be sent to the Server.
A task is something that has to be performed by the Client on a regular interval, which helps us to make sure the machine is in good health and available. For example, if we have to check whether the CPU usage is more than 90% or not, we can do the something like this:
#!/bin/bash
threshold="90"
cpuUsage=$(top -bn1 | grep "Cpu(s)" | \
sed "s/.*, *\([0-9.]*\)%* id.*/\1/" | \
awk '{print 100 - $1}')
if [ 1 -eq "$(echo "${cpuUsage} > ${threshold}" | bc)" ]
then
>&2 echo "current CPU usage is ${cpuUsage}"
exit 1 # 👈 note this
fiAnd inside the config file, a task can be defined in the below format:
{
"name": "cpu-usage-check",
"cmd": "/path/to/cpu/monitoring/script.sh",
"repeatInterval": 20,
"msg": "CPU usage greater than 90%",
"actionsToBeTaken": [
{
"name": "cancel-backup-process-if-any",
"cmd": "/path/to/that/script"
}
]
}
actionsToBeTaken field defines the set of actions to be performed when the actual task fails. There can be multiple actions as well. For more info on the config file, refer to the section below.
Usage of client:
-c string
path to config file (default "config.json")
-r string
server address in the format IP:PORT (default "localhost:40090")
-sl string
client specific log directory (default "log/self")
-tl string
task execution log directory (default "log/task")
Client process generates two types of logs - self and task logs; where self logs refer to the Client process specific logs like unable to connect to alert server or so and task logs will contain execution history of tasks mentioned in the config file and their errors and outputs if any. The log directory for both can be mentioned via sl and tl flags. Logs are split on a daily basis and stored in respective directories.
| If | Will alert be sent? | Behaviour |
|---|---|---|
| Task completes successfully | No | No alerts. Logs "task completed successfully". |
| Task fails | Yes | Will log the error and output; and: If actionsToBeTaken is mentioned, will proceed with it's execution and then send an alert accordingly:
|
type: JSON
{
"hostname": "h0stnam3",
// (optional)
// If not specified, the client will try to get system hostname.
// Else, `hostname` will be used.
"tasks": [
{
"name": "foo",
// (optional)
// Note: `name` can be helpful to distinguish tasks while reading log files,
// so, it's recommended to give one (ideally separated with dashes).
"repeatInterval": 60,
// (required)
// the time interval after which the task should repeat itself
"cmd": "/path/to/some/script/to/execute.sh",
// (required)
// The command/script to execute.
// Note: If the script failed with exit code != 0, it will trigger an alert.
"msg": "some message that is to be sent to monitoring spoc when cmd fails",
// (required)
// the message that will sent upon failure of script mentioned in `cmd`
"actionsToBeTaken": [
// (optional)
// represents the actions to be taken when task fails.
// Note: all actions are executed sequentially one after other.
{
"name": "action-one",
// (optional)
// Note: `name` can be helpful to distinguish tasks while reading log files,
// so, it's recommended to give one (ideally separated with dashes).
"cmd": "/path/to/some/script/to/execute.sh",
// (required)
// The cmd/script to be executed.
"continueOnFailure": true
// (optional)
// To inform the client whether or not to proceed with the next action in the list.
// If not mentioned, it wont' proceed to next action if current actions fails.
},
{
"name": "action-two",
"cmd": "/path/to/some/script/to/execute.sh"
}
]
},
// example:
{
"name": "ex-archival-mount-point-utilization",
"repeatInterval": 1800,
"cmd": "/home/dbadmin/wd/scripts/mount-point-utilization.sh",
"msg": "mount point usage > 90%",
"actionsToBeTaken": [
{
"name": "delete-arcs-older-than-3-months",
"cmd": "/home/dbadmin/wd/scripts/del-old-arcs.sh",
"continueOnFailure": true
},
{
"name": "delete-old-logs",
"cmd": "/home/dbadmin/wd/scripts/del-old-logs.sh"
}
]
}
]
}The Server runs a WebSocket server to which front-end client apps can connect in order to receive alert messages. The connection endpoint is /ws/connect.
The messages are sent in the below format:
{
"time": "alert generation time",
"id": "alert ID",
"from": "hostname of the machine which generated the alert",
"taskName": "the name of the task which failed",
"short": "msg mentione in config file of the task",
"long": "combined output of the task - error and output",
"status": 0 // or 1
}The status field will be:
- 0 if the task failed, but
actionsToBeTakencompleted successfully - 1 if the task failed and
actionsToBeTakenis not specified or any one of the actions mentioned has failed.
WDC is a front-end client that's written for WD. Go check it out here.