feat: 新增 tiny_python_expr 最小 RL 示例#60
Open
HansBug wants to merge 2 commits into
Open
Conversation
245344d to
ad95a98
Compare
Member
Author
|
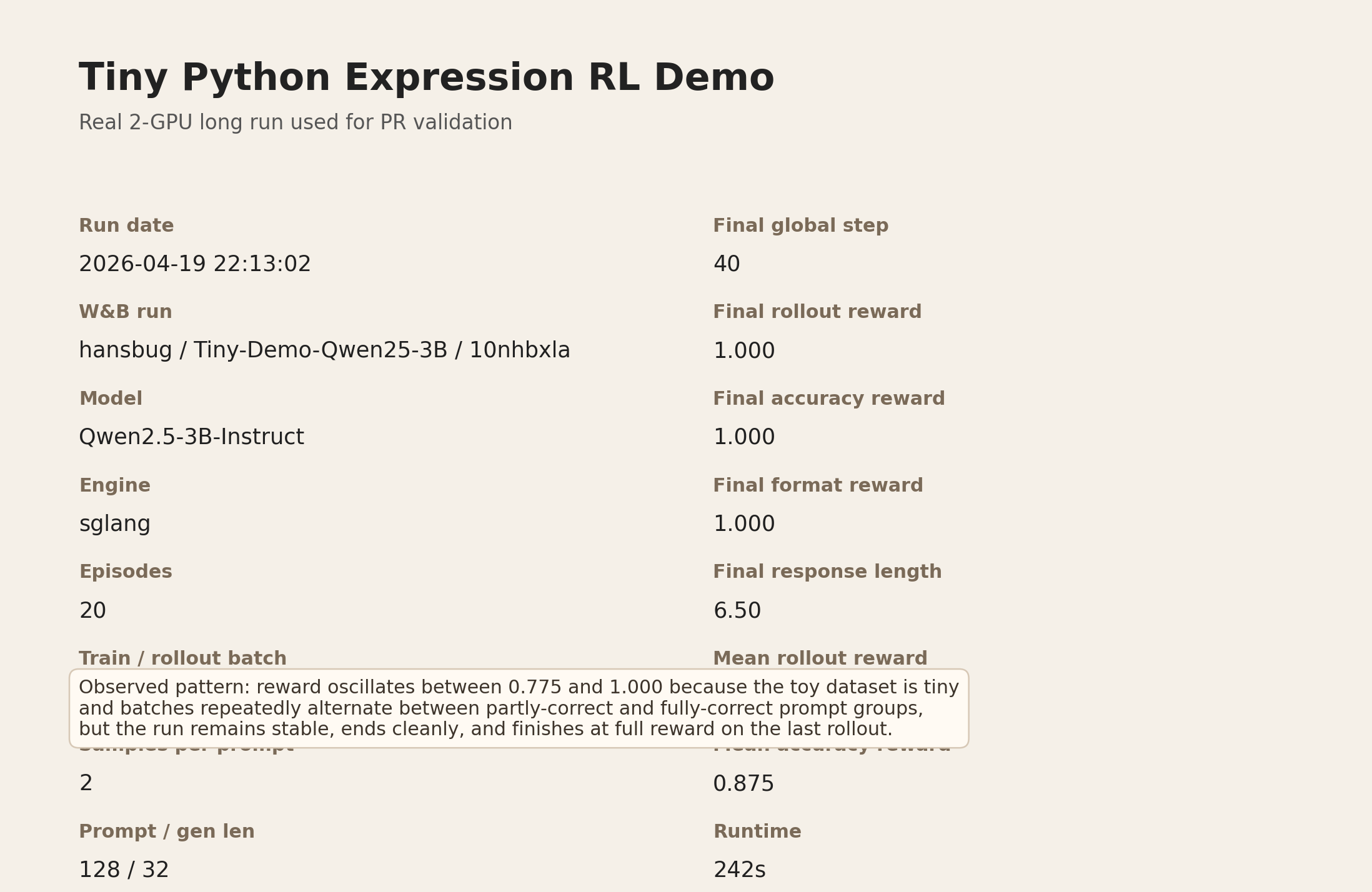
补一份基于当前 1. 本次实验对应的真实运行
2. 关键启动配置这次不是本地单卡试跑,而是实际 2 卡 worker 上完成的完整长运行。核心配置如下:
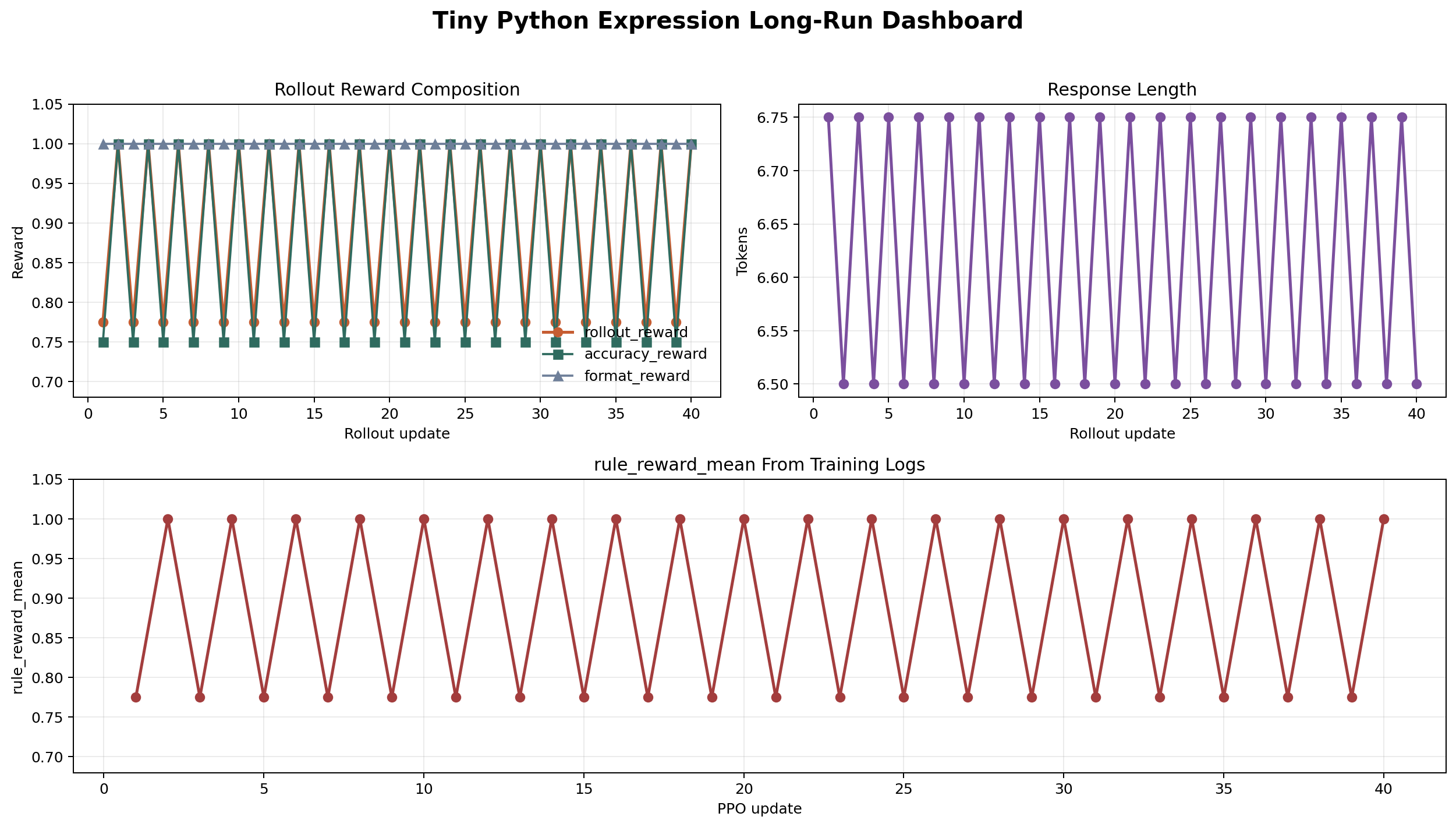
3. 核心结果结论这次 run 是完整跑完的,最终结果如下:
如果把整个 20-episode、40 次 rollout update 都看进去,这次 run 的整体统计是:
我这里对这次 run 的判断是:
4. 图表Summary Card
Reward Dashboard
Sample Rollout Cases
5. 对这组图怎么解读
如果后续还需要,我可以继续补两类附加材料:
|

This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
1 participant
Add this suggestion to a batch that can be applied as a single commit.This suggestion is invalid because no changes were made to the code.Suggestions cannot be applied while the pull request is closed.Suggestions cannot be applied while viewing a subset of changes.Only one suggestion per line can be applied in a batch.Add this suggestion to a batch that can be applied as a single commit.Applying suggestions on deleted lines is not supported.You must change the existing code in this line in order to create a valid suggestion.Outdated suggestions cannot be applied.This suggestion has been applied or marked resolved.Suggestions cannot be applied from pending reviews.Suggestions cannot be applied on multi-line comments.Suggestions cannot be applied while the pull request is queued to merge.Suggestion cannot be applied right now. Please check back later.
改动说明
examples/tiny_python_expr下新增一个最小纯文本 RL examplebuild_dataset.py现场生成,格式可直接接 LightRFT 训练入口format + correctnesstrain_colocate.py是自包含的最小训练入口,只保留这个例子真正需要的参数run_qwen25_3b.sh作为本地和集群 worker 共用的最小启动脚本.gitignore,忽略运行时生成的data/、artifacts/和__pycache__/run_rlaunch.sh,完整rlaunch流程直接写进README.md和README_zh.mdSKIP_DATASET_BUILD=1以避免覆盖已导出的数据目录结构
build_dataset.py:生成 train/test split,并导出 Hugging FaceDatasetDictreward_models_utils.py:规则 reward 逻辑train_colocate.py:最小训练入口run_qwen25_3b.sh:最小启动脚本README.md/README_zh.md:中英文使用说明与rlaunch流程验证
bash -n examples/tiny_python_expr/run_qwen25_3b.shpython3 -m py_compile examples/tiny_python_expr/build_dataset.py examples/tiny_python_expr/reward_models_utils.py examples/tiny_python_expr/train_colocate.pypython3 examples/tiny_python_expr/build_dataset.py --output_dir /tmp/tiny_python_expr_repo_check --train_size 2 --test_size 1 --seed 123python3 examples/tiny_python_expr/build_dataset.py --output_dir /tmp/tiny_python_expr_dataset_doc_check --train_size 4 --test_size 2 --seed 42说明
upstream/main重新整理,只包含examples/tiny_python_expr相关改动,不再混入dev/st的其他内容WANDB_MODE=offlineLIGHTRFT_WANDB_API_KEY或WANDB_API_KEY,并设置真实可用的WANDB_ORG