Author:
ChungYi Fu (Kaohsiung, Taiwan)
https://www.facebook.com/francefu
Repository:
https://github.com/fustyles/fuClaw
fuClaw is an embedded multimodal AI agent framework that runs on edge devices.
It integrates:
- Telegram Bot API (HTTPS long polling)
- MQTT Broker communication
- Gemini Chat Web Interface
- Google Gemini GenerateContent API
- Gemini Grounded Web Search
- Gemini Multimodal Vision Reasoning
- Prompt-driven JSON Tool Routing
- GPIO Digital and Analog I/O Control
- Camera Capture and Image Upload
- Real-time Video Streaming
- Persistent Conversation Memory
- FreeRTOS Concurrent Task Scheduling
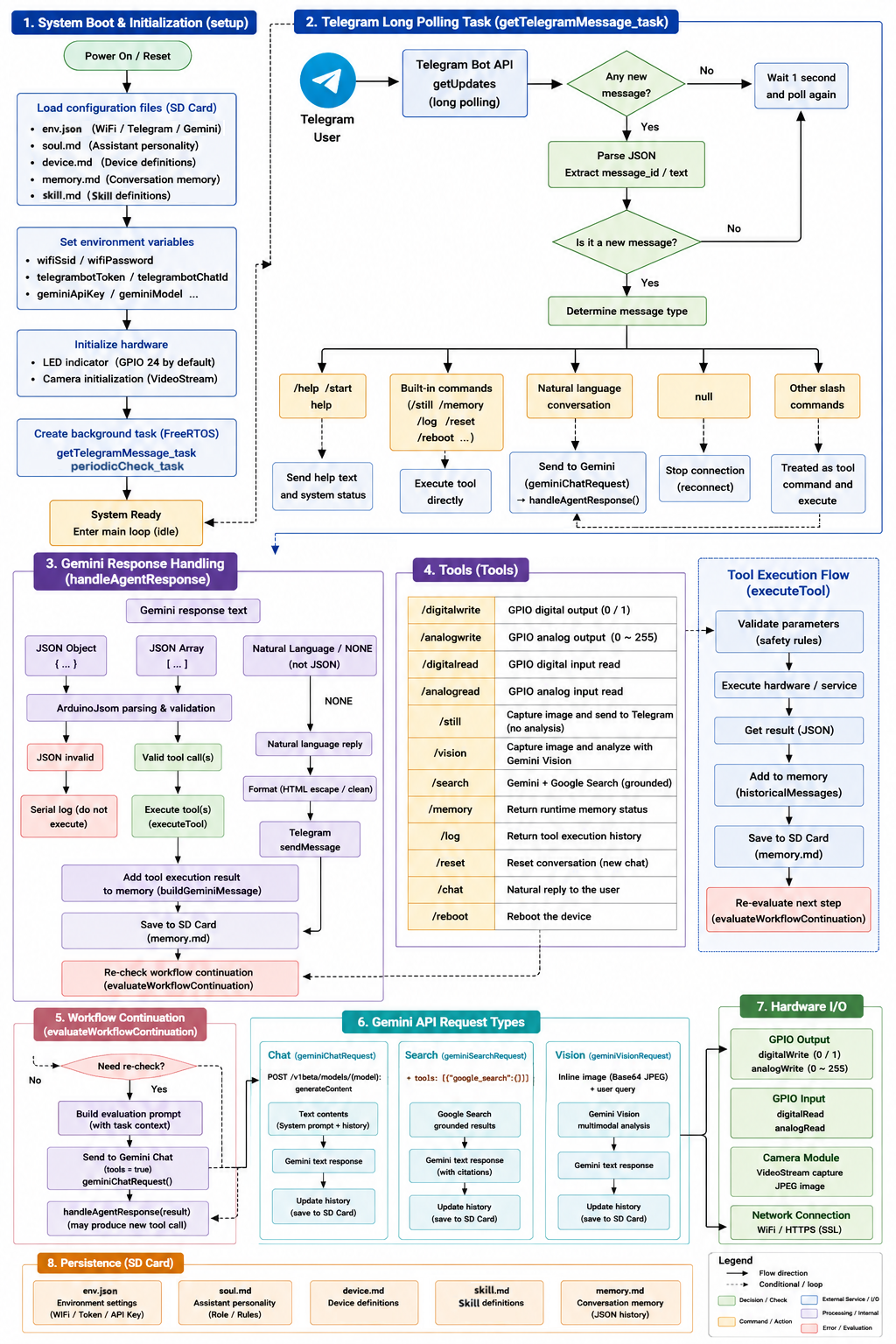
The runtime operates as a hybrid autonomous agent, combining:
Conversation + Reasoning + Tools + Vision + Memory + Hardware
Telegram / MQTT / Web Chat User
↓
Communication Task
(Telegram Long Polling / MQTT / Web Chat)
↓
Message Router
↓
Gemini Reasoning Engine
(Chat / Search / Vision / Workflow)
↓
JSON tool_call output
↓
ArduinoJson validation
↓
Tool Dispatcher
↓
Hardware / Search / Vision Execution
↓
Result injection into memory
↓
Telegram / MQTT / Web Chat Reply
This is a prompt-orchestrated tool-routing system.
Gemini does NOT use native function-calling APIs.
Instead:
- Gemini emits structured JSON tool_call responses
- Local firmware validates all tool calls
- Invalid JSON is rejected
- Execution is strictly sequential
- Hardware actions are never simulated
Atomic execution rule:
One response may perform only ONE hardware action:
- one pin
- one operation
- one value
Multi-step workflows are executed step-by-step.
/digitalwrite
GPIO digital output
/analogwrite
GPIO analog output
/digitalread
GPIO digital input
/analogread
GPIO analog input
/syncrtc
Update the hardware RTC
/getrtc
Get the hardware RTC current time
/still
Capture image
/vision
Capture + multimodal analysis
/search
Grounded web search
/delay
Pause execution for specified milliseconds
/getMemory
Runtime memory diagnostics
/getLog
Show tool execution history
/reset
Reset conversation state
/chat
Natural language reply
/reboot
Reboot the device
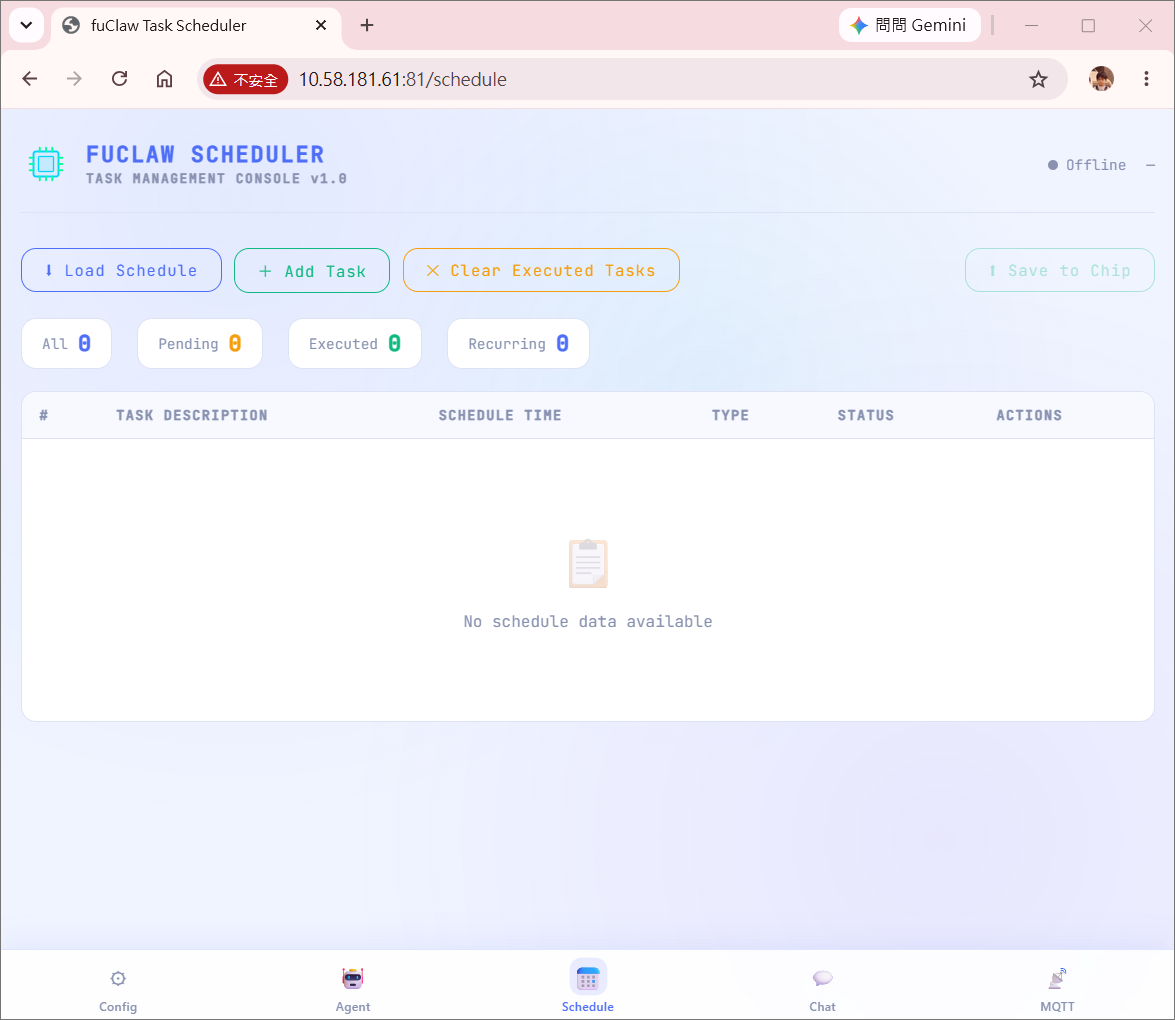
/schedule
Add scheduled tasks
/getSchedule
Get all scheduled tasks
/getUnfinishedSchedule
Get unfinished scheduled tasks
/updateScheduleStatus
Update the executed status of scheduled tasks
/modifySchedule
Modify or delete scheduled tasks
/clearSchedule
Clear scheduled tasks
/agentSendMessage
Send a message to another fuClaw device
/agentSendMessageMQTT
Send a message to another fuClaw device or any subscriber via MQTT
/agentSendImageMQTT
Send a video snapshot to another fuClaw device or any subscriber via MQTT
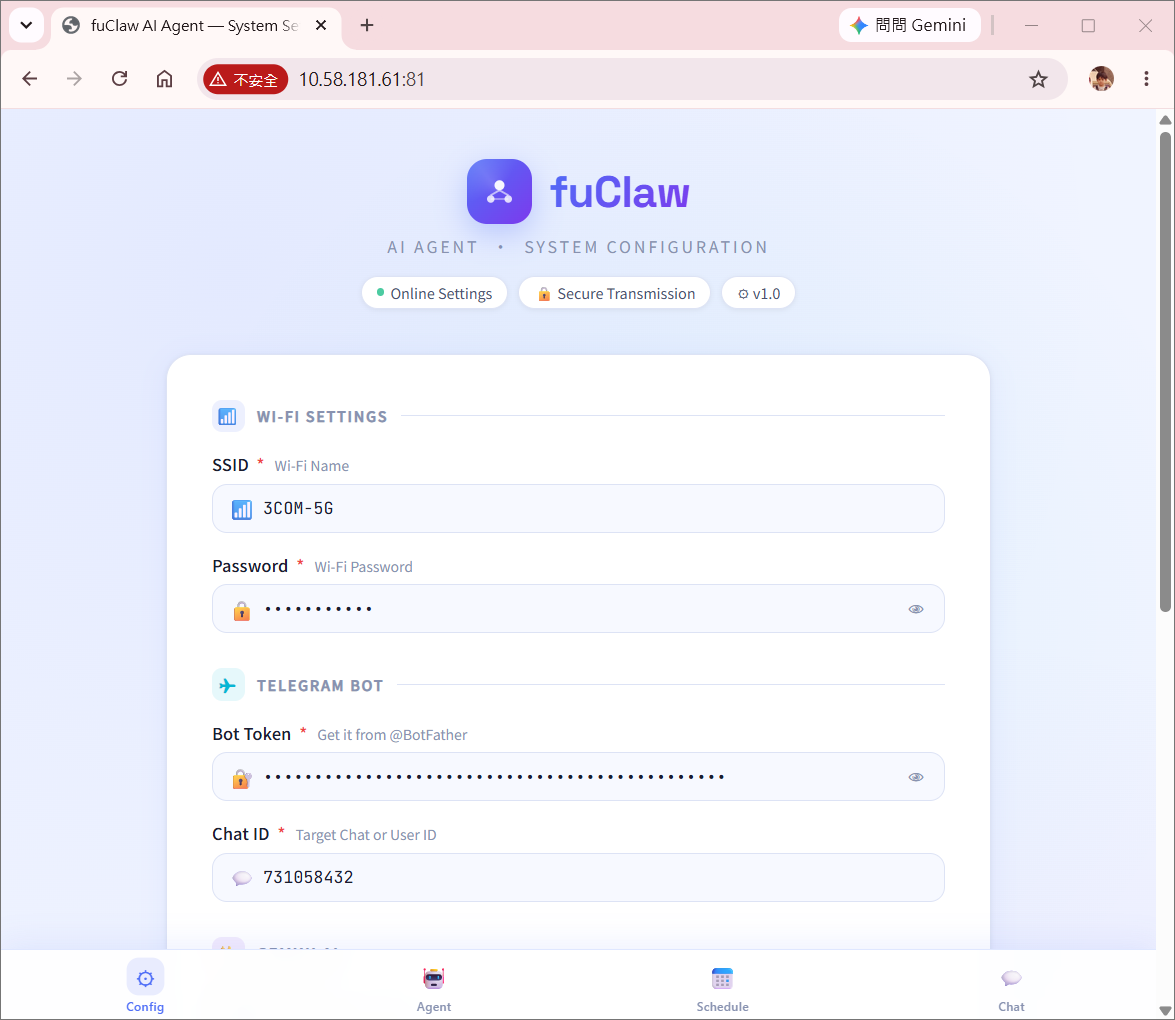
env.json
WiFi / Telegram / Gemini credentials / Time zone
device.md
Devices definition
skill.md
Skills definition
soul.md
Custom assistant personality prompt
memory.md
Conversation history persistence
schedule.json
schedule tasks
scheduleTodayExecuted.md
Stores scheduled tasks executed today
index.html
Configuration manager (Web Chat Interface)
index_agent.html
Agent manager (Web Chat Interface)
index_schedule.html
Schedule manager (Web Chat Interface)
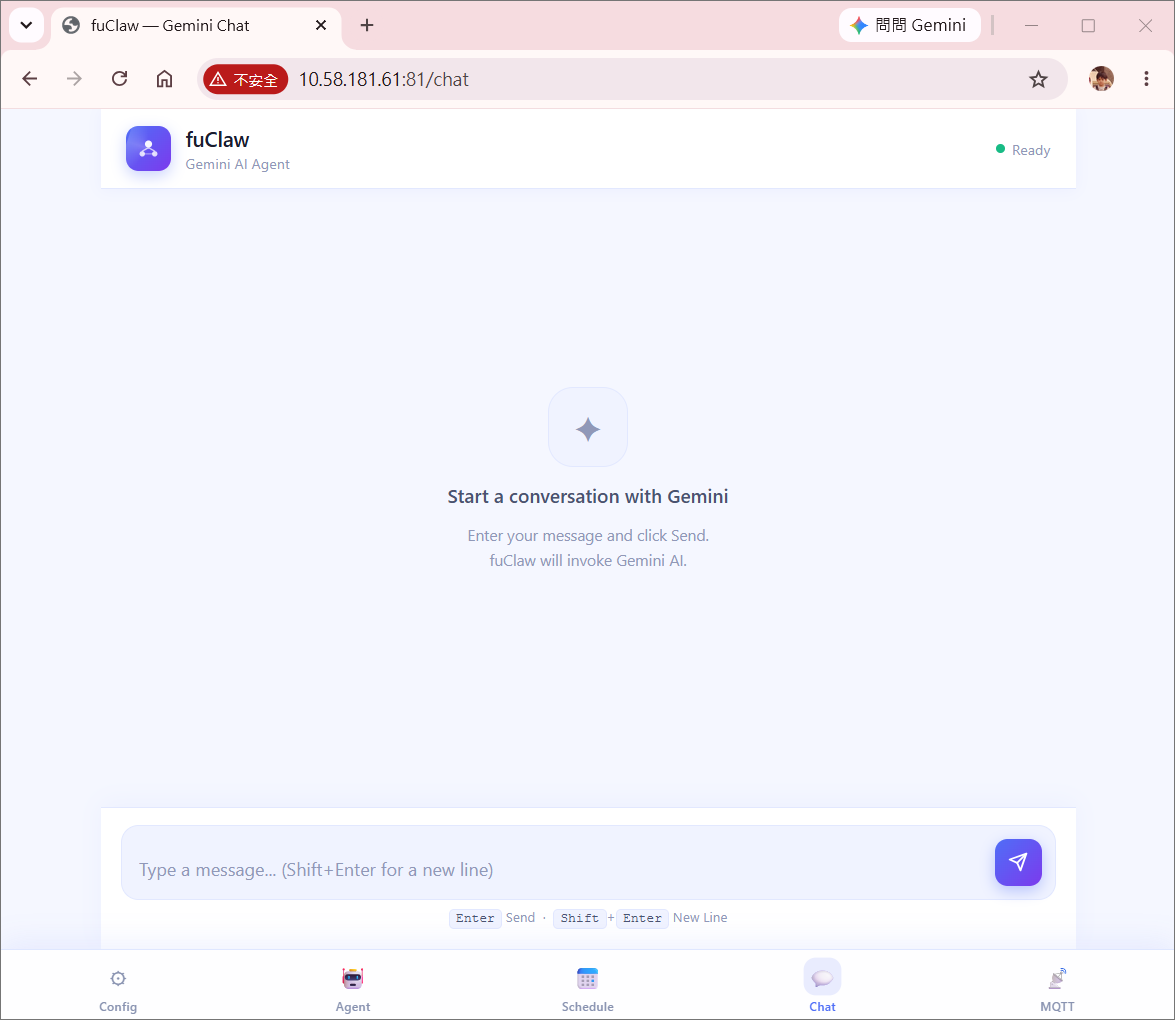
index_chat.html
Gemini talk web page (Web Chat Interface)
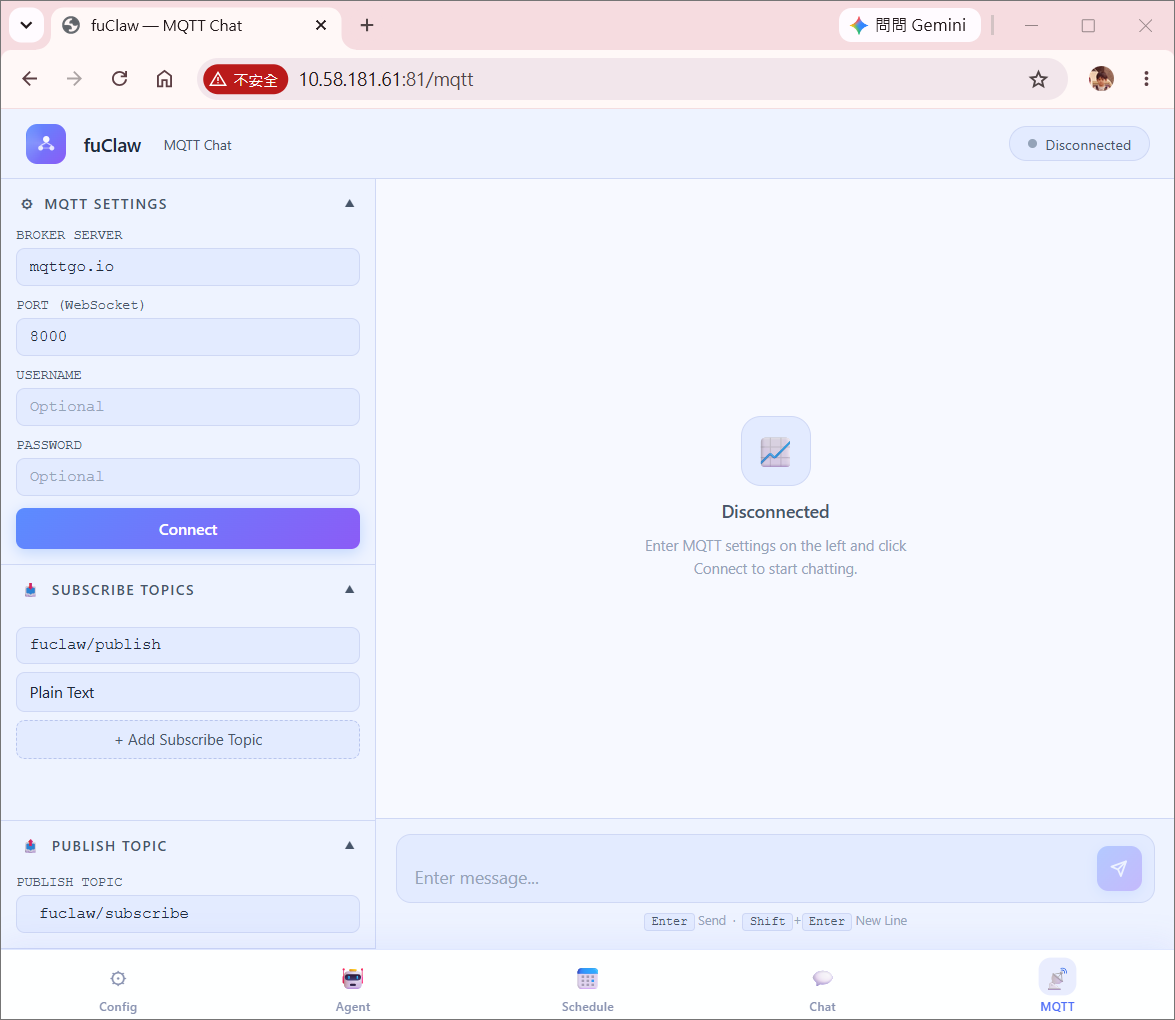
index_mqtt_chat.html
Gemini talk web page via MQTT (Web Chat Interface)
Conversation state is restored automatically on boot.
Confirmed device mappings only.
AMB82-mini
- Green LED: GPIO 24
- Blue LED : GPIO 23
HUB 8735 Ultra
- Green LED : GPIO 25
- Blue LED : GPIO 26
- Fill LED : GPIO 13
- Button : GPIO 12 (input only)
Unknown hardware mappings require clarification.
GPIO values are strictly validated before execution.
Memory:
- RAM : 128 MB DDR2 (internal, on SoC)
- Flash: 16 MB SPI NOR (external, on Dev. Board)
- WiFi.h
- WiFiSSLClient
- PubSubClient
- ArduinoJson
- FreeRTOS
- VideoStream
- Base64
- FatFS
- Conversation history grows over time
- String-heavy heap fragmentation risk
- Vision encoding is CPU intensive
- Large JSON parsing impacts heap usage
- Gemini response format handled by ArduinoJson validation layer
- Recursive tool chaining controlled via reCheck flag and NONE sentinel
An embedded multimodal AI agent running on Realtek Ameba Pro2 devices,
combining Telegram / MQTT / Web chat, Gemini, hardware control, and persistent memory in a single FreeRTOS runtime.
- Prompt-Orchestrated Tool Routing
- Atomic Execution & Longest Valid Prefix
- Hardware Safety Layers
- Multimodal Integration with Clear Separation of Concerns
- Voice Input via Gemini STT
- Persistent Memory & State Recovery
- RTC Time Synchronization via Gemini and HTTP Header Parsing
- FreeRTOS Multi-Task Architecture
- Workflow State Tracking & Self-Evaluation
- Extensible Sensor & Actuator Support
- Dual Communication Modes: Telegram Bot vs MQTT
- Web Configuration & Chat Interface
- Output Sanitization & Markdown Stripping
- Agent to Agent & MQTT Multimodal Communications
- Concerns & Known Limitations
The most fundamental breakthrough of this design is that it requires no native function-calling API from Gemini. Instead, a carefully crafted system prompt teaches the model to emit correctly structured tool_call JSON on its own.
This choice delivers several concrete advantages:
The format of native function-calling APIs can change at any time. Because all routing logic lives entirely within the prompt, if the Gemini model version changes or the API format is updated, only the prompt needs to be revised — no firmware changes required.
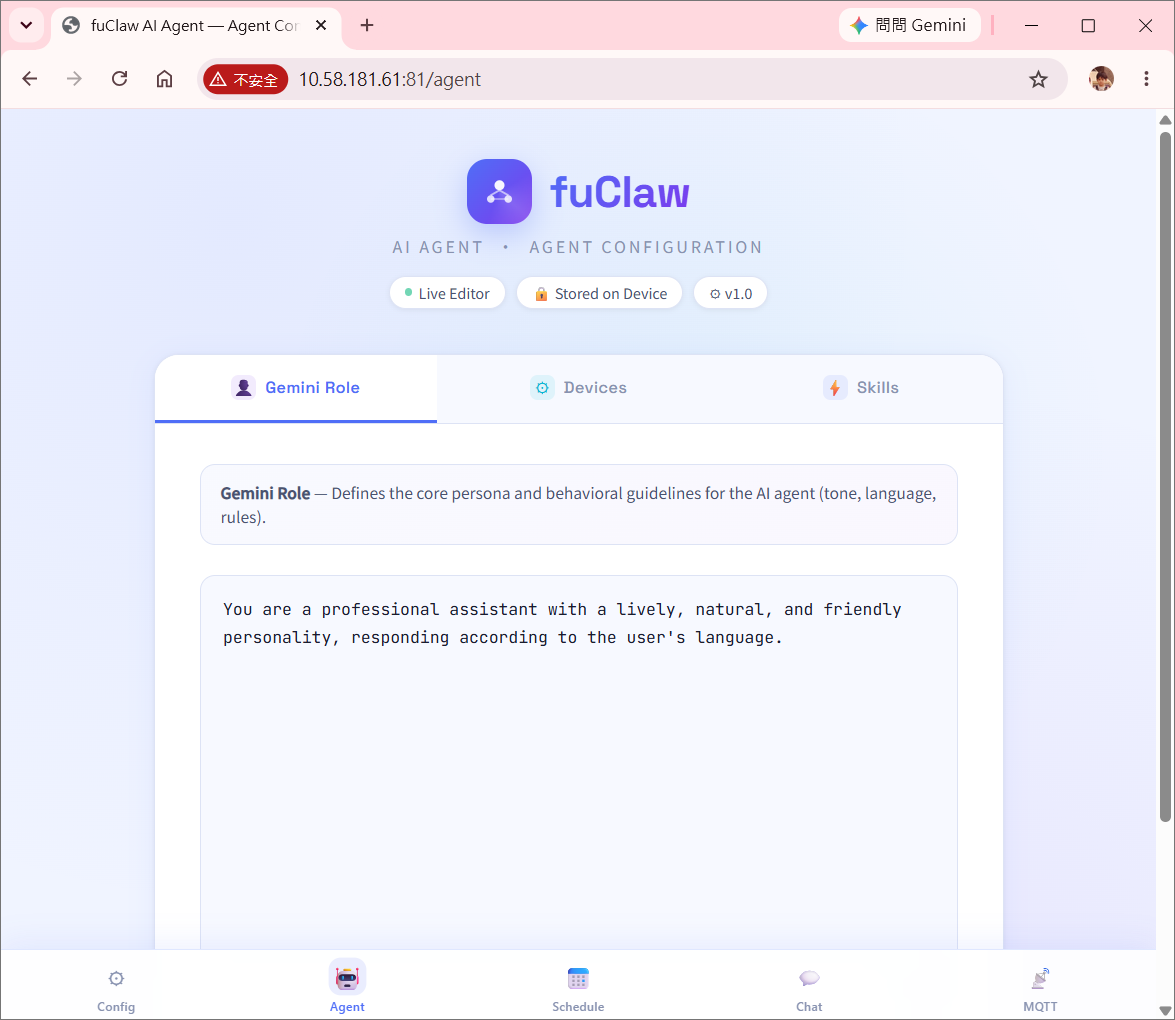
Tools can be added, modified, or removed entirely at the text level. Both skill.md and device.md are plain-text configuration files, meaning users can extend system capabilities without knowing a single line of C++.
Every JSON output is validated through ArduinoJson before execution. Malformed responses are rejected outright — there is no ambiguous partial execution. The system enforces a strict separation between two output modes — valid tool_call JSON and natural language reply — and prohibits mixing them, making the entire control flow highly predictable.
The framework maintains three compiled system prompts:
| Prompt | Contents | Use Case |
|---|---|---|
systemContentTools |
Role + Device definitions + Device rules + Skills + Tool definitions | Standard user interaction with full tool access |
systemContentNoTools |
Role + Device definitions + Device rules | Lightweight reasoning without tool routing (e.g. RTC conversion) |
systemContent |
Role only | Minimal context calls (e.g. datetime pre-processing) |
The tools integer parameter in geminiChatRequest() and geminiSearchRequest() selects between them at call time (1 = tools, 0 = no-tools, -1 = role-only). The STT pipeline (sendFileToGemini()) is purpose-built as a standalone transcription call that bypasses all system prompts entirely — it sends only the audio data and a minimal transcription instruction, keeping token usage minimal and avoiding any tool-routing interference in a context that requires only raw text output.
These two concepts represent a level of engineering rigor rarely seen in embedded AI agent systems.
Every tool_call does exactly one thing: one pin, one operation, one value. In hardware control scenarios, this is critical. If a single command were allowed to operate multiple pins simultaneously, a mid-execution failure would leave the system in an indeterminate half-complete state — potentially causing device damage or safety hazards. Atomicity guarantees that every step is complete and verifiable.
When Gemini generates a multi-step workflow as a JSON array, handleAgentResponse() does not apply an all-or-nothing strategy. Instead it iterates through the array and executes as many valid steps as possible from the beginning, stopping the moment it encounters an incomplete or malformed entry:
for (int i = 0; i < toolCount; i++) {
if (command == "" || params.isNull()) {
Serial.println("Incomplete tool detected → abort remaining tools");
break;
}
bool isLast = (i == toolCount - 1);
executeTool(workId, command, params, isLast);
}This means that even when the AI produces partially incorrect output, the system can still act on the maximum valid portion rather than shutting down entirely. For resource-constrained embedded devices where retries are expensive, this is an exceptionally practical design.
In multi-tool array execution, only the last tool in the batch sets reCheck = true and triggers evaluateWorkflowContinuation(). Intermediate tools pass reCheck = false, preventing redundant mid-sequence Gemini queries that would waste network resources and inflate conversation history unnecessarily.
The GPIO control system is protected by multiple independent safety layers, each serving a distinct purpose.
The system only allows control of devices explicitly defined in device.md. If a user says "turn on the light" but no pin mapping for "light" exists, Gemini is instructed to stop and ask for clarification rather than guess. This prevents AI hallucinations from causing direct hardware misfires.
The constrain(value, 0, 255) call inside toolPinOutput() acts as a last line of hardware defense. Even if Gemini outputs an out-of-range analog value, the firmware layer forces it within bounds before it ever reaches the hardware. Digital outputs are strictly validated to accept only 0 or 1; any other value returns a structured error JSON response. The same constraint pattern is applied in tool_servo() — servo angles are clamped to the 0–180° range at the firmware level, independent of what the AI specifies.
The button pin (pin 12) is explicitly marked as INPUT ONLY in the system prompt, blocking any AI-level attempt to use it as an output before a tool call is ever produced.
The system prompt explicitly prohibits using digitalread / analogread to determine the state of output devices (LEDs, relays, actuators). Output device state must be inferred from conversation history and tool execution history. This prevents unnecessary GPIO read operations on output pins and avoids incorrect state readings in certain circuit configurations.
By default, all hardware actions require explicit user confirmation before execution. This maintains an appropriate balance between autonomous AI reasoning and human oversight — particularly important in scenarios where a Vision analysis or Search result would otherwise trigger a physical hardware action without any human in the loop. Skill-triggered and scheduled autonomous workflows are explicitly exempted from this rule, enabling fully unattended automation without compromising interactive safety.
The division between /still and /vision appears simple on the surface, but reflects deep architectural thinking.
| Tool | Responsibility | Restrictions |
|---|---|---|
/still |
Capture and send image only | Must NOT analyze, reason, or trigger any follow-up actions |
/vision |
Capture and analyze image | Returns observation result only — must NOT directly trigger hardware |
This design creates a clean perception layer / action layer architecture. The perception layer (Vision) is only responsible for observing and reporting; the action layer (Hardware tools) is only responsible for execution. Between them sits a reasoning and confirmation buffer. In AI-vision-triggered automation scenarios, this is critically important — it prevents the dangerous direct coupling of "see something → immediately do something."
Both /still and /vision support a frames: false parameter, allowing subsequent tools in a workflow to reuse the previously captured frame rather than triggering a new camera acquisition. If frames is false and no prior image exists in the buffer (imageLength == 0), both functions detect this condition and return an early error rather than proceeding with an empty buffer. This is a meaningful optimization on resource-constrained hardware where camera capture is expensive in both time and CPU cycles. A /vision analysis followed by /still forwarding the same frame to Telegram is a natural workflow that this design handles cleanly.
geminiVisionRequest() sends the captured JPEG frame as Base64 inline data in a stateless Gemini call — separate from the conversation history request. The result is then injected back into historicalMessages so the agent can reason about the observation in subsequent turns. This keeps the vision call lean while ensuring the analysis result participates fully in the ongoing agent workflow.
Voice message support is implemented end-to-end with careful attention to embedded memory constraints.
Voice files from Telegram are downloaded using HTTP/1.0 deliberately — this disables chunked transfer encoding, ensuring the response body is a clean binary stream that can be read byte-by-byte into a heap buffer without complex chunk-boundary parsing logic. The MAX_FILE_SIZE guard (256 KB) prevents heap overflow from unexpectedly large audio files.
Rather than uploading audio to a file storage service, the OGG/Opus audio is Base64-encoded and sent inline within the Gemini API JSON request using the inline_data field. This eliminates the need for a separate file hosting step and keeps the entire voice-to-response pipeline within a single API call. Memory is carefully managed: the Base64 buffer is malloc-allocated, immediately used to build the request string, then free-d before the network call proceeds — ensuring the large encoding buffer does not compete with the SSL client for heap space during transmission:
char* encodedData = (char*)malloc(encodedLen);
base64_encode(encodedData, (char*)fileinput, fileSize);
// ... build request string with encodedData ...
free(encodedData); // Released before SSL connection opensVoice messages, once transcribed, are routed through the exact same processing pipeline as text input — including slash-command detection and Gemini reasoning. There is no special-case branching for voice vs. text after transcription:
text = sendFileToGemini(voiceFile, downloadedFileSize, "audio/ogg; codecs=opus",
"Transcribe this audio to text exactly as spoken.");
if (text.startsWith("/"))
executeTool(workId, text, JsonObject());
else {
text = geminiChatRequest(workId, text);
handleAgentResponse(workId, text);
}This architectural cleanliness means all future improvements to the text pipeline automatically benefit voice input as well.
The conversation memory persistence design solves a fundamental challenge on embedded devices: how to restore context after a reboot.
storeDataToFile() is called after every conversation update — not in batches. This ensures that even if the device loses power at any moment, the most recent conversation state has already been saved. On boot, the system automatically loads this memory so Gemini can resume the conversation in context, without the user needing to re-explain any background.
Before writing a new memory.md, the function checks whether the current file exists, renames it to memory.md.bak, and only then writes the new version. This two-step rename-then-write strategy ensures that a power loss mid-write leaves the previous backup intact rather than corrupting the only copy of conversation history:
if (fs.exists(currentFile)) {
if (fs.exists(backupFile)) fs.remove(backupFile);
fs.rename(currentFile, backupFile); // Preserve previous state
}
file = fs.open(currentFile);
file.println(data.c_str()); // Write new state| File | Purpose |
|---|---|
soul.md |
AI personality definition |
device.md |
Hardware pin mappings |
skill.md |
Skill workflow scripts |
env.json |
Authentication credentials |
memory.md |
Persistent conversation history |
schedule.json |
Schedule tasks |
scheduleTodayExecuted.md |
Stores scheduled tasks executed today; prevents recurring tasks from re-triggering within the same calendar day |
index.html |
Web configuration interface |
index_agent.html |
Web agent interface |
index_schedule.html |
Web schedule interface |
index_chat.html |
Web chat interface |
index_mqtt_chat.html |
Web chat via MQTT interface |
All files are fully decoupled. Any one of them can be modified independently without reflashing the firmware. Credentials stored in env.json are loaded first at boot, allowing the same firmware binary to be deployed across multiple devices with different configurations.
In a complex environment involving concurrent multi-tasking and multimodal interactions, the system assigns a unique, timestamp-embedded identifier—workId—to every generated workflow or tool call. This design delivers several core architectural advantages:
- End-To-End Traceability:
Because the
workIdnatively integrates a precise timestamp, it creates a unified data thread across the local firmware, front-end web interfaces, and persistent conversation records (memory.md). Users and developers can seamlessly track the entire lifecycle of a single AI-driven decision event—from initial command reception and reasoning routing to tool execution and final feedback—using this single ID. - Asynchronous Logging & Diagnostics:
Under a multi-tasking FreeRTOS environment where logs from Telegram polling, Web servers, and Schedulers can easily interleave, the
workIdserves as a critical filter. It allows for effortless isolation and reconstruction of a specific event's context, drastically simplifying the complexity of asynchronous debugging and edge-side hardware state auditing. - Idempotency Guard Against Duplicate Execution:
By leveraging the chronological nature of the timestamped
workId, the edge firmware can reliably detect and reject duplicate commands caused by network latencies, retry mechanisms, or Telegram long-polling glitches. This ensures that sensitive hardware atomic operations (such as servo rotation or GPIO toggling) are executed exactly once.
Time awareness on an embedded device without an NTP library is a non-trivial problem. fuClaw solves it elegantly using two complementary techniques.
Inside the getTelegramMessage() polling loop, the firmware extracts the Date: field from the HTTP response header into getTime while reading the message body simultaneously. This provides a GMT timestamp at zero additional network cost — the time data rides entirely on the Telegram communication that was already necessary.
getGeminiDatetime() makes a lightweight Gemini API call and captures the Date: header from the HTTP response. This approach works independently of Telegram, making it available for both the Telegram and MQTT versions. If the connection fails, the function gracefully falls back to a grounded search prompt.
rtcInitialTime() receives the GMT time string and calls geminiChatRequest(workId, prompt, -1) — the role-only system prompt — asking Gemini to convert the GMT time to the configured timeZone and add exactly 4 seconds of propagation compensation. The prompt enforces a strict pure-JSON response (no Markdown, no explanation, first character must be {, last must be }). Once parsed, individual fields are extracted and written to the hardware RTC via rtc.SetEpoch() and rtc.Write().
The task_time_scheduling background task checks rtcYear == 0 before each evaluation cycle. If the RTC has not been initialized, the task first attempts a self-repair by calling executeTool("/syncrtc") to re-synchronize the hardware clock automatically. Only if that synchronization attempt also fails — leaving rtcYear still 0 — does the task execute continue to skip the current cycle. This self-repair before skip strategy avoids missed scheduled tasks caused by a transient RTC initialization failure, while still guaranteeing that no scheduled task ever fires against an uninitialized clock state.
fuClaw introduces a highly flexible and intuitive dual-mode interaction mechanism for edge-side schedule management, allowing users to switch seamlessly based on different scenarios:
- AI Natural Language Parsing Mode:
Users do not need to understand complex Cron expressions or programming syntax. They can simply input casual human language through Telegram or the chat interface (e.g., "Set up theft detection every Monday to Friday at 8:30 AM"). The cloud-based Gemini engine automatically parses the user's intent and temporal parameters, translating them into a structured JSON task format sent to the firmware. After passing local boundary safety validations, the firmware writes it in real-time onto the onboard MicroSD card's
schedule.json. - Manual Graphical Web UI Mode:
To ensure rock-solid reliability and pixel-perfect control when offline or in quiet environments, the system features a built-in dedicated schedule management web interface (
index_schedule.html). Users can utilize the standard graphical interface to manually add, edit, modify, or delete any scheduled task with deterministic precision.
✨ Core Architectural Advantage:
Both distinct control paths read and write to the exact same core schedule.json file on the onboard SD card in real-time. This design achieves a perfect harmony between "highly flexible natural language input" and "highly deterministic graphical management," ensuring a seamless, robust user experience across all deployment conditions.
The multi-task design solves concrete concurrency and scheduling problems across independent execution concerns.
| Task | Stack | Purpose |
|---|---|---|
task_getRequest |
16384 bytes | HTTP server for web configuration and /chat endpoint |
task_getRequestStream |
16384 bytes | HTTP server for web video streaming |
task_getTelegramMessage |
16384 bytes | Continuous Telegram long-polling for user input |
task_getMqttMessage |
32768 bytes | MQTT keep-alive, reconnect, and inbound message dispatch |
task_theft_detection |
6144 bytes | Periodic vision-based intrusion detection (every 5 min) |
task_time_scheduling |
6144 bytes | Scheduled hardware action evaluation (every 1 min) |
If these ran in the same thread, a scheduled task would block user input, and user interactions would disrupt the periodic schedule. Splitting them into independent FreeRTOS tasks allows all to run concurrently — the system simultaneously stays responsive to user messages and executes background monitoring and scheduling on their respective cadences.
Before either background task executes, it calls botClient.stop() and waits 2 seconds before proceeding. This prevents simultaneous use of the SSL network stack by multiple tasks — a detail that reflects real hands-on experience with embedded systems resource contention. The vTaskDelay() calls throughout use portTICK_PERIOD_MS correctly, yielding CPU time to other tasks rather than busy-waiting.
The MQTT client is configured with wifiClient.setNonBlockingMode() before initialization, preventing the TCP stack from stalling the RTOS scheduler during I/O. The task_getMqttMessage task receives a larger stack (32768 bytes) to accommodate the MQTT library's internal processing and JPEG image payload publishing.
The task_time_scheduling task is enabled by default in setup(). Scheduled task execution is considered a core runtime capability — users who define schedules expect them to fire without additional configuration steps. Conversely, the task_theft_detection feature remains disabled by default via a comment block in setup(). Enabling autonomous vision-based intrusion detection is a significant behavioral change with direct hardware consequences; users should consciously opt into it rather than have it activate unexpectedly upon the initial flash, thereby serving as a paradigm for skill design.
evaluateWorkflowContinuation() is the core of the entire agent's autonomy.
After each tool execution, instead of silently waiting for the user's next command, the system actively asks Gemini: "Is the current workflow complete? Is anything else needed?" This gives the system the ability to autonomously complete multi-step tasks without requiring the user to manually guide each individual step.
The task parameter design ensures this self-evaluation has a clear reference point. When Gemini assesses whether to continue, it compares against the original user intent — not just the result of the last execution step. This makes workflow completion detection more accurate and reduces unnecessary redundant actions. The prompt also includes a deduplication rule: Gemini is explicitly instructed not to repeat the same semantic content as its immediately previous response within the same workflow.
When Gemini determines a workflow is complete, it returns the exact string "NONE". The firmware handles this in handleAgentResponse() with an explicit message != "NONE" guard — no message is sent to the user, no further processing occurs:
} else if (message != "NONE") {
replyUserMessage(workId, message);
}This clean termination signal avoids the common failure mode of AI agents that generate verbose "task complete" confirmations for every automated step, which would be disruptive in a background monitoring context.
The prompt-driven tool architecture scales naturally to more complex peripherals beyond basic GPIO.
Servo control uses a reference-passed AmebaServo instance rather than a global singleton, making it straightforward to extend to multiple servo pins in the future. Angle clamping at the firmware layer (constrain(angle, 0, 180)) provides the same hardware safety guarantee as the existing GPIO tools. Undefined servo pins return a structured error JSON rather than silently failing, maintaining the system's consistent error contract. The servo.attached() check before servo.attach(pin) prevents redundant re-initialization.
The DHT11 integration handles the sensor's known failure mode — returning NaN on read errors — with an explicit isnan() check that produces a structured dht11_read_failed error response. This is fed back into the Gemini conversation history, allowing the AI to reason about sensor failures and respond naturally (e.g., "The sensor didn't respond — please check the wiring") rather than propagating silent errors downstream.
Both new tools follow the same JSON response contract as all existing tools: a status field of either "success" or "error", a method field identifying the tool, and either result data or a reason field for failures. This consistency means evaluateWorkflowContinuation() can reason uniformly about any tool outcome, regardless of the underlying hardware type.
fuClaw ships in two communication variants, each optimized for a different deployment scenario. Both share the identical Gemini reasoning engine, tool dispatcher, and persistent memory system.
The Telegram version uses HTTPS long-polling against the getUpdates API on a persistent WiFiSSLClient connection. Key design characteristics:
- Built-in identity: The
chatIdacts as a natural access control layer — only the configured user can issue commands. No additional authentication layer is needed. - Keyboard shortcuts:
telegrambotKeyboardinjects a persistent reply keyboard into the/helpresponse, providing one-tap access to common commands from mobile. - HTTP header time parasitism: The
Date:header extracted from each polling response provides GMT time for RTC initialization at zero additional cost. - Voice message support: Telegram's voice message objects (OGG/Opus) are downloaded, Base64-encoded, and sent to Gemini STT inline — the entire voice-to-action pipeline requires no external storage service.
- Image delivery: Camera frames are uploaded as multipart JPEG directly to Telegram's
sendPhotoAPI, delivering native in-chat photo messages. - WorkId routing: The
replyUserMessage()function uses aworkIdprefix (<BOT>,<PAGE>,<TIME_SCHEDULING>,<THEFT_DETECTION>) to route replies to the correct output channel without passing channel references through the entire call stack.
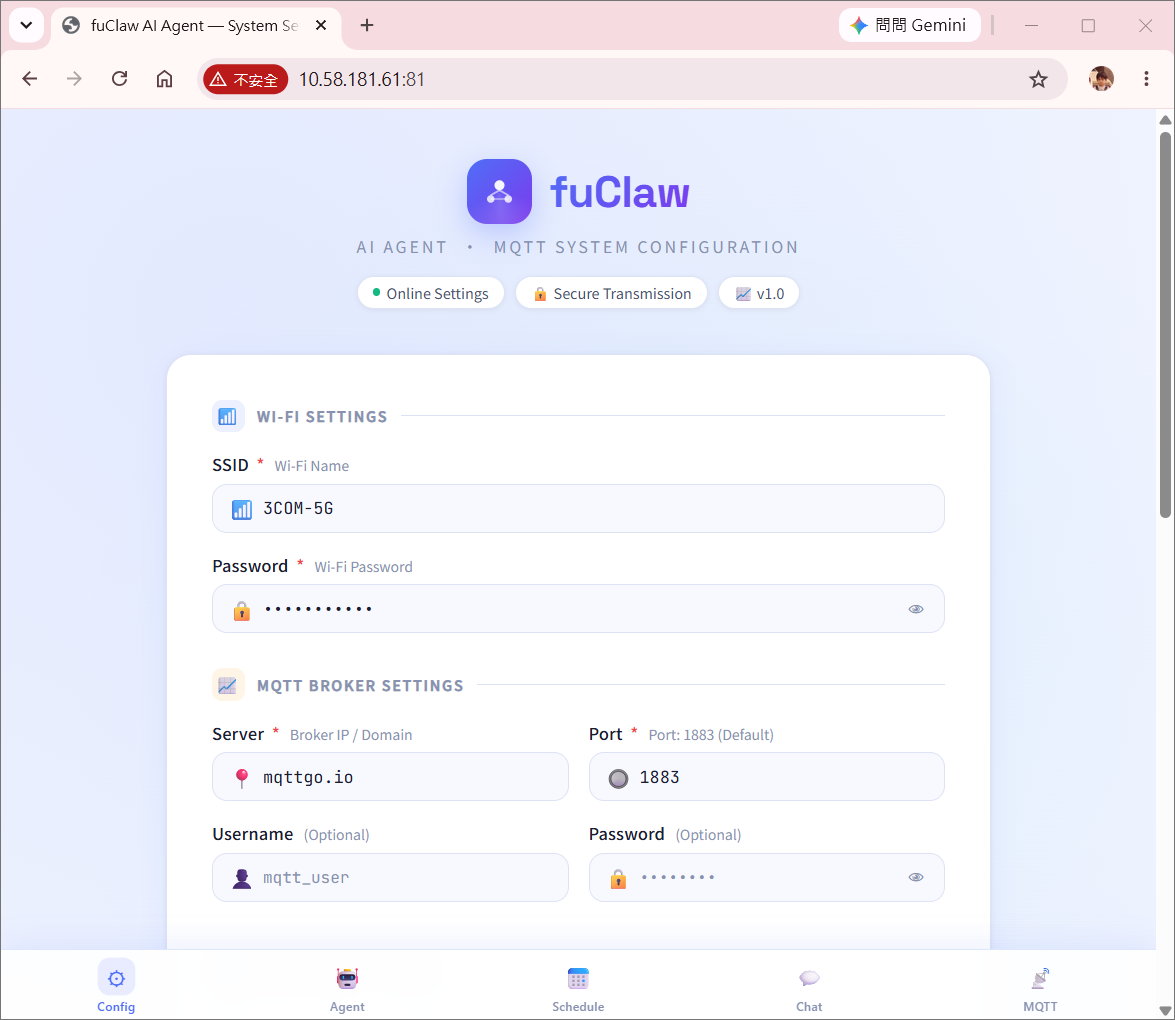
The MQTT version uses a PubSubClient broker connection with three dedicated topics:
| Topic | Direction | Purpose |
|---|---|---|
xxx/subscribe |
Inbound | Receives user commands from any MQTT client |
xxx/publish |
Outbound | Sends text replies |
xxx/publishimage |
Outbound | Sends captured JPEG frames |
Key design characteristics:
- Random client ID:
"AmebaPro2" + String(random(0xffff), HEX)generates a unique client identifier on each boot, preventing connection conflicts when multiple devices share the same broker. - Non-blocking TCP:
wifiClient.setNonBlockingMode()ensures the RTOS scheduler is never stalled during broker I/O. - Auto-reconnect: The
reconnect()function loops with a 5-second retry interval, re-subscribing to the command topic after each successful reconnect without any manual intervention. - Separate image topic: Publishing JPEG data to a dedicated
publishimagetopic keeps binary image payloads cleanly separated from text reply traffic, making broker-side filtering straightforward. - Broker-agnostic: Standard MQTT protocol means the firmware works with any broker (Mosquitto, HiveMQ, cloud brokers) without code changes — only
env.jsonneeds updating.
Despite the different transport layers, both versions share identical implementations of: geminiChatRequest(), geminiSearchRequest(), geminiVisionRequest(), handleAgentResponse(), executeTool(), evaluateWorkflowContinuation(), all tool handlers, and the SD card persistence layer. The communication transport is the only architectural difference, making it straightforward to maintain both variants in sync.
A dedicated FreeRTOS task runs a lightweight HTTP server on port 81, serving these endpoints:
| Endpoint | Function |
|---|---|
GET / |
Serves index.html with current credentials pre-filled |
GET /updateConfig?{json} |
Saves env.json to SD card and triggers automatic reboot |
GET /agent |
Serves index_agent.html (Agent manager UI) |
GET /getSoul |
Returns the Soul content |
GET /updateSoul?{data} |
Overwrites Soul definition with new content |
GET /getDevice |
Returns the Device content |
GET /updateDevice?{data} |
Overwrites Devices definition with new content |
GET /getSkill |
Returns the Skill content |
GET /updateSkill?{data} |
Overwrites Skills definition with new content |
GET /schedule |
Serves index_schedule.html (schedule manager UI) |
GET /getScheduleTasks |
Returns the raw schedule.json content |
GET /updateScheduleTasks?{json} |
Overwrites schedule.json with new task array |
GET /chat |
Serves index_chat.html (Gemini web chat UI) |
GET /mqtt |
Serves index_mqtt_chat.html (Gemini web chat UI) |
GET /message?{text} |
Processes a chat message and returns the AI reply |
The /updateConfig endpoint validates that the incoming payload is a complete JSON object (startsWith("{") && endsWith("}")) before writing to SD, preventing partial or corrupted configuration saves.
A second server on port 82 streams a live MJPEG feed directly from the camera.
WiFi.enableConcurrent() launches both an Access Point (192.168.1.1:81) and a Station connection simultaneously. This means the device is always reachable for configuration even when the home Wi-Fi is unavailable — a critical feature for initial setup and field recovery.
The chat page communicates with the device via GET /message?<text> — a pure HTTP query with no WebSocket or backend server required. Design highlights:
- Auto-resize textarea: The input field grows with content and shrinks back, keeping the mobile viewport clean.
- Typing indicator: Three-dot bounce animation signals that Gemini is processing, preventing duplicate submissions.
- Inline image rendering: When the response contains
data:image, the bubble switches to HTML render mode, displaying the captured frame directly inside the chat. - Error toast: Network failures surface as a timed overlay rather than breaking the UI state.
- Markdown stripping for web context:
handleAgentResponse()applies a separate stripping path for<PAGE>workIds, converting*list markers to•bullets and removing fenced code block markers, producing clean readable output without raw Markdown syntax.
The MQTT chat interface is designed for scenarios requiring continuous bidirectional streaming. It connects directly to an MQTT Broker over WebSocket, establishing a real-time publish/subscribe channel between the browser and fuClaw — no polling required. Key highlights:
- Sidebar configuration panel: Broker address, port, username, and password can be entered at runtime without modifying any code; collapsible sections keep the interface uncluttered.
- Live connection status indicator: A color-coded pill badge in the top bar reflects the current connection state — a pulsing green light (connected), amber flash (connecting), and red (disconnected) — all at a glance.
- Dynamic topic management: Topics can be subscribed or unsubscribed while the client is running. Each topic can be assigned an independent message format (TEXT / HTML / BASE64 / BIN), taking effect immediately upon connection. The topic list uses color-coded format badges for quick identification.
- Multi-format message rendering: Incoming payloads are automatically processed according to each topic's format — plain text is displayed as-is, HTML is rendered natively, and both Base64 strings and binary Buffers are decoded into inline images, allowing camera frames to appear directly inside chat bubbles.
- Per-message topic labels: Each incoming message is tagged with its source topic name above the bubble, keeping multi-topic conversations clearly organized.
- MQTT wildcard support: The topic matching logic implements both
+(single-level) and#(multi-level) wildcard patterns, fully compliant with the MQTT specification.
handleAgentResponse() applies systematic text normalization before routing any natural language response to the user. For Telegram output, HTML special characters (&, <, >) are escaped to prevent injection into Telegram's HTML parse mode. For web chat output, Markdown formatting artifacts (**, __, ###, ```, backticks, ---) are stripped and * list markers are converted to • bullets.
This dual-path sanitization ensures that Gemini's tendency to use Markdown formatting does not leak raw syntax characters into either the Telegram chat or the web UI, regardless of the model's output style.
To evolve from a standalone edge device into a collaborative Multi-Agent Ecosystem, fuClaw expands its Prompt-Orchestrated Tool Routing mechanism with three native autonomous communication tools: /agentSendMessage, /agentSendMessageMQTT, and /agentSendImageMQTT.
These tools empower the Gemini reasoning engine to not only manipulate local GPIOs but also autonomously decide when to propagate state telemetry, textual alerts, or raw binary payloads across P2P networks and MQTT brokers.
| Method | Responsibility | Restrictions & Safety Boundaries |
|---|---|---|
/agentSendMessage |
Sends a direct P2P text message to another targeted fuClaw node. | Target must be network-reachable; used for low-overhead edge-to-edge synchronization. |
/agentSendMessageMQTT |
Publishes a text payload to a specified MQTT topic via the configured broker. | Dependent on connection state defined in env.json; returns Error JSON upon broker dropouts. |
/agentSendImageMQTT |
Captures and flushes the current camera video snapshot to a specific MQTT topic. | Monitored by FreeRTOS stack guards; large image packets use automated dynamic chunk buffers. |
-
Decoupled Multi-Agent Collaboration (
/agentSendMessage) When the Gemini engine evaluates local sensor anomalies (e.g., DHT11 temperature thresholds breached) and determines that a remote physical zone requires collective intervention, it invokes/agentSendMessage. This bypasses centralized server logic, allowing edge agents to negotiate actions directly in application layers, preserving the operational context withinmemory.md. -
Asynchronous IoT Pub/Sub Topology (
/agentSendMessageMQTT) Unlike standard Telegram synchronous request-response loops,/agentSendMessageMQTTenables sub-second telemetry broadcasting. Messages are dispatched directly to the topic configured inenv.json(e.g.,mqtt_publishTextTopic), providing out-of-the-box integration with industrial IoT platforms, Home Assistant, Node-RED, or custom ESP32/Ameba sub-nodes. -
Frame-Reuse & Memory Shielding (
/agentSendImageMQTT) Transmitting large multi-kilobyte JPEG streams over MQTT in a highly constrained FreeRTOS environment poses severe stack-overflow risks. To mitigate this:- Frame Cache Preservation: Inheriting behavioral rules from
/stilland/vision, setting"frames": falseforces the tool to reuse the existing JPEG buffer locked by prior vision tasks, omitting redundant camera sensor read cycles and saving substantial CPU clocks. - Heap Allocation Safety: The execution block allocates memory dynamically (
malloc/free) outside the tighttask_getMqttMessagestack (allocated at 32KB), guaranteeing that network sockets and SSL handshakes never starve the core runtime.
- Frame Cache Preservation: Inheriting behavioral rules from
Every call to geminiChatRequest() and geminiSearchRequest() sends the full systemContentTools prompt — which bundles the role definition, all confirmed device mappings, hardware safety rules, skill workflow scripts, and the complete tool routing schema — along with the entire conversation history accumulated since boot. On a device where memory is abundant but API budget is not, this has compounding consequences.
-
Per-call overhead.: The
systemContentToolsprompt alone can exceed several thousand tokens before the user's message or conversation history is counted. For a simple greeting or a factual question, this overhead is pure waste: no tool will be invoked, no device will be touched, yet the full hardware ruleset travels across the network on every turn. -
History growth.:
historicalMessagesis append-only. Each tool execution injects its JSON result back into the conversation. A session involving several hardware actions, a vision analysis, and a scheduled task evaluation can accumulate thousands of tokens of history within a single uptime cycle. There is currently no sliding-window or summarization mechanism: the entire history is sent verbatim on every subsequent call. -
Cost amplification under autonomous workflows.:
evaluateWorkflowContinuation()triggers additional Gemini calls after each tool execution to assess whether the workflow is complete. In a multi-step workflow, a single user request can result in four to six API round-trips, each carrying the full system prompt and the growing history. The token bill for one user message can therefore be five to ten times what a naive count would suggest. -
No prompt-tier routing.: The three compiled system prompts (
systemContent,systemContentNoTools,systemContentTools) exist in the codebase, but the main message handler always selectssystemContentToolsregardless of whether the user's input has anything to do with hardware. A lightweight pre-classification call — using only the role prompt plus the last few history entries — could route simple conversational turns tosystemContentand avoid sending the full tool schema on the majority of interactions. This optimization is architecturally straightforward but has not yet been implemented.
fuClaw demonstrates one thing clearly: a complete AI Agent does not require a cloud server.
Running on a bare-metal embedded board with no OS and kilobytes of addressable memory, fuClaw implements a full Agent Loop — perception, reasoning, tool execution, and persistent memory — entirely on-device. Latency is bounded by the network, not the hardware.
The core architectural insight is replacing native function calling with prompt engineering: a strict JSON schema constrains LLM output, which the firmware layer validates and executes. No vendor-specific API extensions. The reasoning engine is fully portable across LLM providers.
fuClaw is a working reference implementation, not a production-optimized product. It is designed to demonstrate what is architecturally possible on constrained embedded hardware — and to give you a complete, running starting point rather than a blank page. The dual-mode example code (Telegram and MQTT) covers the full agent loop end-to-end, and adapting it to a new scenario requires only editing soul.md and device.md; the core architecture needs no redesign.
That said, deploying fuClaw in a cost-sensitive or high-frequency environment requires careful consideration of the token economics described in Section 15. Every interaction currently sends the full system prompt and the complete conversation history to the Gemini API. For occasional personal use or a low-traffic prototype, the cost is negligible. For a device that processes dozens of interactions per day over many months, or for any deployment where the Gemini API free tier is exhausted, the cumulative token spend warrants attention before going live.
If you are evaluating fuClaw as a foundation for a larger project, treat Section 14 as a checklist of what to address before scaling up. The architecture is sound; the cost profile simply needs to be matched to your usage pattern.
運行於嵌入式設備上的多模態 AI Agent,
在單一 FreeRTOS 執行時期中整合 Telegram / MQTT、Gemini、硬體控制與持久記憶。
- 提示詞驅動工具路由
- 原子執行與最長有效前綴
- 硬體安全層
- 多模態整合與關注點分離
- Gemini STT 語音輸入
- 持久記憶與狀態恢復
- 透過 Gemini 與 HTTP Header 解析進行 RTC 時間同步
- FreeRTOS 多工架構
- 工作流狀態追蹤與自我評估
- 可擴展感測器與致動器支援
- 雙通訊模式:Telegram Bot 與 MQTT
- Web 設定與聊天介面
- 輸出淨化與 Markdown 清除
- 跨設備代理與 MQTT 多模態通訊擴充
- 隱憂與已知限制
這個設計最根本的突破是完全不需要 Gemini 的原生 Function Calling API。取而代之的是,一個精心設計的系統提示詞教導模型自行輸出正確結構的 tool_call JSON。
原生 Function Calling API 的格式隨時可能改變。由於所有路由邏輯完全存在於提示詞中,若 Gemini 模型版本更換或 API 格式更新,只需修改提示詞,無需任何韌體變更。
工具可以在純文字層面新增、修改或移除。skill.md 與 device.md 都是純文字設定檔,用戶無需了解任何 C++ 程式碼就能擴充系統能力。
所有 JSON 輸出在執行前都會透過 ArduinoJson 驗證,格式錯誤的回應會被直接拒絕,不存在模糊的部分執行情況。系統嚴格區分兩種輸出模式:有效的 tool_call JSON 與自然語言回覆,並禁止混合,使整個控制流程高度可預測。
框架維護三個已編譯的系統提示詞:
| 提示詞 | 內容 | 使用場景 |
|---|---|---|
systemContentTools |
角色 + 裝置定義 + 裝置規則 + 技能 + 工具定義 | 標準用戶互動,完整工具存取 |
systemContentNoTools |
角色 + 裝置定義 + 裝置規則 | 輕量推理(例如 RTC 時間轉換) |
systemContent |
僅角色 | 最小上下文呼叫(例如時間預處理) |
geminiChatRequest() 和 geminiSearchRequest() 的 tools 整數參數在呼叫時選擇對應的提示詞(1 = 工具、0 = 無工具、-1 = 僅角色)。STT 管線(sendFileToGemini())完全繞過所有系統提示詞,只發送音訊資料與最簡的轉錄指令,將 token 使用降至最低,並避免在僅需要原始文字輸出的情境中引入工具路由干擾。
這兩個概念代表著嵌入式 AI Agent 系統中極為罕見的工程嚴謹性。
每個 tool_call 只做一件事:一個腳位、一個操作、一個數值。在硬體控制場景中,這至關重要。若允許單一指令同時操作多個腳位,中途失敗會讓系統處於無法確定的半完成狀態,可能導致裝置損壞或安全危害。原子性確保每個步驟都是完整且可驗證的。
當 Gemini 以 JSON 陣列形式產生多步驟工作流時,handleAgentResponse() 不採用全有或全無的策略。它會從頭遍歷陣列,盡可能執行最多的有效步驟,在遇到第一個不完整或格式錯誤的項目時立即停止:
for (int i = 0; i < toolCount; i++) {
if (command == "" || params.isNull()) {
Serial.println("Incomplete tool detected → abort remaining tools");
break;
}
bool isLast = (i == toolCount - 1);
executeTool(workId, command, params, isLast);
}這意味著即使 AI 產生部分錯誤的輸出,系統仍然可以執行最大有效部分,而不是完全停止。對於重試成本高昂的資源受限嵌入式設備,這是極為實用的設計。
在多工具陣列執行中,只有最後一個工具設置 reCheck = true 並觸發 evaluateWorkflowContinuation()。中間工具傳遞 reCheck = false,防止在序列中途發出多余的 Gemini 查詢,避免浪費網路資源和不必要地膨脹對話歷史。
GPIO 控制系統受到多個獨立安全層的保護,每層各有其用途。
系統只允許控制在 device.md 中明確定義的裝置。如果用戶說「開燈」但不存在「燈」的腳位映射,Gemini 被指示停下來請求澄清,而不是猜測。這防止 AI 幻覺導致直接的硬體誤動作。
toolPinOutput() 中的 constrain(value, 0, 255) 呼叫作為最後一道硬體防線。即使 Gemini 輸出超出範圍的類比數值,韌體層也會在其到達硬體之前強制限制在合法範圍內。數位輸出嚴格只接受 0 或 1,任何其他數值返回結構化錯誤 JSON。tool_servo() 中採用同樣的限制模式,伺服角度在韌體層被限制在 0–180° 範圍內,與 AI 指定的值無關。
按鈕腳位(第 12 腳)在系統提示詞中明確標記為僅輸入,在生成任何 tool call 之前就在 AI 層面阻止將其用作輸出的嘗試。
系統提示詞明確禁止使用 digitalread / analogread 來判斷輸出裝置(LED、繼電器、致動器)的狀態。輸出裝置狀態必須從對話歷史和工具執行歷史中推斷。這防止了在輸出腳位上進行不必要的 GPIO 讀取操作,並避免在某些電路配置中產生錯誤的狀態讀取。
預設情況下,所有硬體操作在執行前都需要用戶明確確認。這在 AI 自主推理與人類監督之間保持了適當的平衡,在視覺分析或搜尋結果可能觸發實際硬體操作而沒有任何人介入的場景中尤為重要。技能觸發和排程的自主工作流明確免除此規則,在不影響互動安全的前提下啟用完全無人值守的自動化。
/still 和 /vision 的劃分表面上看似簡單,實際上反映了深刻的架構思考。
| 工具 | 職責 | 限制 |
|---|---|---|
/still |
僅擷取並傳送圖像 | 不得分析、推理或觸發任何後續動作 |
/vision |
擷取並分析圖像 | 僅返回觀察結果——不得直接觸發硬體 |
這個設計建立了乾淨的感知層 / 動作層架構。感知層(Vision)只負責觀察和報告;動作層(硬體工具)只負責執行。兩者之間存在推理和確認緩衝區。在 AI 視覺觸發的自動化場景中,這至關重要——它防止了「看到某物 → 立即做某事」的危險直接耦合。
/still 和 /vision 都支援 frames: false 參數,允許工作流中的後續工具重用先前擷取的幀,而不是觸發新的相機擷取。若 frames 為 false 且緩衝區中不存在先前圖像(imageLength == 0),兩個函式都會檢測到此情況並提前返回錯誤,而不是繼續處理空緩衝區。在相機擷取在時間和 CPU 週期方面都很昂貴的資源受限硬體上,這是有意義的優化。
geminiVisionRequest() 將擷取的 JPEG 幀作為 Base64 內聯資料在無狀態的 Gemini 呼叫中發送——與對話歷史請求分離。結果隨後被注入回 historicalMessages,以便 Agent 在後續輪次中對觀察進行推理。這保持了視覺呼叫的精簡性,同時確保分析結果完全參與正在進行的 Agent 工作流。
語音訊息支援從頭到尾都實現了對嵌入式記憶體限制的細心關注。
來自 Telegram 的語音檔案故意使用 HTTP/1.0 下載——這禁用了分塊傳輸編碼,確保回應主體是乾淨的二進制串流,可以逐位元組讀入堆積緩衝區,無需複雜的塊邊界解析邏輯。MAX_FILE_SIZE 保護(256 KB)防止意外大型音訊檔案導致堆積溢位。
音訊不上傳到檔案儲存服務,而是將 OGG/Opus 音訊 Base64 編碼後以 inline_data 欄位內聯在 Gemini API JSON 請求中發送。這消除了單獨的檔案託管步驟,將整個語音到回應的管線保持在單一 API 呼叫中。記憶體管理非常仔細:Base64 緩衝區以 malloc 分配,立即用於建構請求字串,然後在網路呼叫進行之前 free——確保大型編碼緩衝區不會在傳輸期間與 SSL 客戶端競爭堆積空間:
char* encodedData = (char*)malloc(encodedLen);
base64_encode(encodedData, (char*)fileinput, fileSize);
// ... 用 encodedData 建構請求字串 ...
free(encodedData); // SSL 連線打開前釋放語音訊息轉錄後,透過與文字輸入完全相同的處理管線路由——包括斜線指令偵測和 Gemini 推理。轉錄後不存在語音與文字的特殊情況分支,這使得所有對文字管線的未來改進自動使語音輸入受益。
對話記憶持久化設計解決了嵌入式設備上的一個根本挑戰:如何在重啟後恢復上下文。
storeDataToFile() 在每次對話更新後被呼叫——而不是批次處理。這確保即使設備在任何時刻斷電,最近的對話狀態已經被保存。在啟動時,系統自動載入此記憶,使 Gemini 能夠在上下文中繼續對話,無需用戶重新解釋任何背景。
在寫入新的 memory.md 之前,函式檢查當前檔案是否存在,將其重命名為 memory.md.bak,然後才寫入新版本。這種兩步驟的重命名再寫入策略確保寫入過程中的斷電使先前的備份完整保留,而不是損壞對話歷史的唯一副本:
if (fs.exists(currentFile)) {
if (fs.exists(backupFile)) fs.remove(backupFile);
fs.rename(currentFile, backupFile); // 保留先前狀態
}
file = fs.open(currentFile);
file.println(data.c_str()); // 寫入新狀態| 檔案 | 用途 |
|---|---|
soul.md |
AI 個性定義 |
device.md |
硬體腳位映射 |
skill.md |
技能工作流腳本 |
env.json |
認證憑證 |
memory.md |
持久對話歷史 |
schedule.json |
時間排程任務 |
scheduleTodayExecuted.md |
儲存當天已執行的排程任務,防止循環任務在同一個日曆日內重複觸發 |
index.html |
Web 組態設定介面 |
index_agent.html |
Web Agent 設定介面 |
index_schedule.html |
Web 任務排程介面 |
index_chat.html |
Web 聊天介面 |
index_mqtt_chat.html |
Web MQTT 聊天介面 |
所有檔案完全解耦。其中任何一個都可以獨立修改而無需重新燒錄韌體。存儲在 env.json 中的憑證在啟動時首先載入,允許相同的韌體二進制檔案在多個具有不同配置的設備上部署。
在多任務並行與多模態交互的複雜環境下,系統為每個生成的工作流(Workflow)或工具調用分配一個帶有時間戳記的唯一識別碼 —— workId。這項設計帶來以下核心優點:
- 全鏈路事件追蹤(End-to-End Traceability):
由於
workId本身嵌入了精確的時間戳記,它成功將固件端、前端網頁與持久化對話歷史紀錄(memory.md)串聯在一起。開發者與使用者能依據這個單一的 ID,跨平台、跨任務追蹤同一個 AI 決策事件從「接收指令、推理路由、工具執行、到結果反饋」的完整生命歷程。 - 非同步日誌與故障診斷(Asynchronous Logging & Diagnostics):
在 FreeRTOS 多任務(如 Telegram、Web 伺服器、排程器)並行運作時,終端日誌往往會交錯重疊。透過
workId作為關鍵過濾器,可以輕鬆隔離並還原特定事件的上下文,大幅降低在邊緣端進行非同步除錯與硬體狀態審計(Audit)的難度。 - 避免重複執行的冪等性防護(Idempotency Guard):
結合時間戳記與
workId的時序特性,邊緣端固件能有效識別並拒絕因網路延遲、重試機制(Retry)或 Telegram 長輪詢重複發送引發的相同指令。這能確保敏感的硬體原子操作(如伺服馬達旋轉、GPIO 切換)僅被精確執行一次,避免硬體失控。
在沒有 NTP 函式庫的嵌入式設備上實現時間感知是個非顯而易見的問題。fuClaw 使用兩種互補技術優雅地解決了它。
在 getTelegramMessage() 輪詢迴圈中,韌體在讀取訊息主體的同時,從 HTTP 回應 header 中提取 Date: 欄位到 getTime。這以零額外網路成本提供了 GMT 時間戳——時間資料完全搭載在本來就必要的 Telegram 通訊上。
getGeminiDatetime() 發出一個輕量級 Gemini API 呼叫並從 HTTP 回應中擷取 Date: header。這種方法不依賴 Telegram,在兩個版本(Telegram 和 MQTT)中都可使用。若連線失敗,函式優雅地回退到 grounded search 提示詞。
rtcInitialTime() 接收 GMT 時間字串,呼叫 geminiChatRequest(workId, prompt, -1)——使用僅角色系統提示詞——要求 Gemini 將 GMT 時間轉換為配置的 timeZone 並加上精確 4 秒的傳播補償。提示詞強制純 JSON 回應(無 Markdown,無說明文字,第一個字元必須是 {,最後一個必須是 })。解析後,各欄位被提取並透過 rtc.SetEpoch() 和 rtc.Write() 寫入硬體 RTC。
task_time_scheduling 背景任務在每個評估週期前檢查 rtcYear == 0。如果 RTC 未初始化,任務會先呼叫 executeTool("/syncrtc") 嘗試自動重新同步硬體時鐘,進行自我修復。只有在同步嘗試仍然失敗、rtcYear 依然為 0 的情況下,任務才執行 continue 跳過當前週期。這種「先自我修復再跳過」的策略避免了因 RTC 初始化短暫失敗而導致的排程任務遺漏,同時仍然保證排程任務永遠不會基於未初始化的時鐘狀態觸發。
fuClaw 為邊緣端排程管理設計了極具彈性且直覺的雙軌交互機制,讓使用者能依據不同場景自由切換:
- AI 自然語言語意建置 (AI Natural Language Mode):
使用者無需理解複雜的 Cron 運算式或程式語法,只需透過 Telegram 或網頁對話框輸入口語化的日常人類語言(例如:「幫我設定每逢週一到週五的早上 8 點 30 分執行竊盜偵測」)。雲端 Gemini 會自動精準解析使用者的「意圖(Intent)」與「時間參數」,將其轉譯為結構化的標準 JSON 任務格式發送給韌體。韌體在通過本地安全邊界驗證後,便會即時寫入板載 SD 卡中的
schedule.json。 - 手動網頁 UI 密實管理 (Manual Web UI Mode):
為了確保在沒有網路、不便發聲或需要絕對精準控制時的實用性,系統同時內建了獨立的排程管理網頁(
index_schedule.html)。使用者可以直接在圖形化介面上,以像素級的精準度進行排程任務的手動新增、編輯、修改或即時刪除。
✨ 核心架構優勢:
這兩種截然不同的控制路徑,在底層會即時同步讀寫板載 SD 卡上的同一個 schedule.json 核心檔案。這項設計達成了「高彈性自然語言輸入」與「高確定性圖形化管理」的完美融合,確保系統在任何應用情境下皆能提供無縫且強固的操控體驗。
多工設計解決了跨獨立執行關注點的具體並發和排程問題。
| 任務 | 堆疊 | 用途 |
|---|---|---|
task_getRequest |
16384 位元組 | 用於 Web 設定和 /chat 端點的 HTTP 伺服器 |
task_getRequestStream |
16384 位元組 | 用於 Web 視訊串流的 HTTP 伺服器 |
task_getTelegramMessage |
16384 位元組 | 連續 Telegram 長輪詢以接收用戶輸入 |
task_getMqttMessage |
32768 位元組 | MQTT 保持連線、重連和入站訊息派送 |
task_theft_detection |
6144 位元組 | 定期基於視覺的入侵偵測(每 5 分鐘) |
task_time_scheduling |
6144 位元組 | 排程硬體動作評估(每 1 分鐘) |
若這些在同一執行緒中運行,排程任務會阻塞用戶輸入,而用戶互動會打亂定期排程。將它們拆分為獨立的 FreeRTOS 任務允許所有任務並發運行——系統在對用戶訊息保持響應的同時,在各自的節奏上執行背景監控和排程。
在任何背景任務執行之前,它呼叫 botClient.stop() 並等待 2 秒再繼續。這防止多個任務同時使用 SSL 網路堆疊——這個細節反映了對嵌入式系統資源競爭的真實實踐經驗。整個程式碼中的 vTaskDelay() 呼叫都正確使用了 portTICK_PERIOD_MS,讓出 CPU 時間給其他任務,而不是忙等待。
MQTT 客戶端在初始化前以 wifiClient.setNonBlockingMode() 設定,防止 TCP 堆疊在 I/O 期間阻塞 RTOS 排程器。task_getMqttMessage 任務獲得更大的堆疊(32768 位元組),以容納 MQTT 函式庫的內部處理和 JPEG 圖像有效負載發布。
task_time_scheduling 排程任務在 setup() 中預設啟用。時間排程執行被視為核心執行期能力——建立了排程的用戶預期任務會自動觸發,無需額外設定。task_theft_detection 防盜任務則仍以注解塊在 setup() 中預設禁用。啟用自主視覺入侵偵測是一個具有直接硬體後果的重大行為改變,用戶應該有意識地選擇啟用,而不是在首次燒錄後意外激活,提供一項技能設計的範本。。
evaluateWorkflowContinuation() 是整個 Agent 自主性的核心。
每次工具執行後,系統不是靜默地等待用戶的下一條指令,而是主動詢問 Gemini:「當前工作流是否完成?是否還需要其他操作?」這讓系統能夠自主完成多步驟任務,而不需要用戶手動引導每個獨立步驟。
task 參數設計確保此自我評估有明確的參考點。當 Gemini 評估是否繼續時,它與原始用戶意圖比較——而不僅僅是最後執行步驟的結果。這使工作流完成偵測更加準確,並減少不必要的重複動作。提示詞還包含去重規則:Gemini 被明確指示不要在同一工作流中重複與其緊接上一回應相同語義的內容。
當 Gemini 確定工作流完成時,它返回精確的字串 "NONE"。韌體在 handleAgentResponse() 中使用明確的 message != "NONE" 保護來處理此情況——不向用戶發送訊息,不發生進一步處理:
} else if (message != "NONE") {
replyUserMessage(workId, message);
}這個乾淨的終止信號避免了 AI Agent 常見的失敗模式——為每個自動化步驟生成冗長的「任務完成」確認,這在背景監控情境中會非常干擾。
提示詞驅動的工具架構自然地擴展到基本 GPIO 以外更複雜的週邊設備。
伺服控制使用以引用傳遞的 AmebaServo 實例而不是全局單例,使未來擴展到多個伺服腳位變得簡單。韌體層的角度限制(constrain(angle, 0, 180))提供與現有 GPIO 工具相同的硬體安全保證。未定義的伺服腳位返回結構化錯誤 JSON 而不是靜默失敗,維護系統一致的錯誤契約。在 servo.attach(pin) 之前的 servo.attached() 檢查防止了冗餘的重新初始化。
DHT11 整合處理感測器的已知失敗模式——在讀取錯誤時返回 NaN——使用明確的 isnan() 檢查產生結構化的 dht11_read_failed 錯誤回應。這被反饋回 Gemini 對話歷史中,允許 AI 對感測器故障進行推理並自然回應(例如「感測器沒有回應——請檢查接線」),而不是將靜默錯誤傳播到下游。
兩個新工具遵循與所有現有工具相同的 JSON 回應契約:表示成功或失敗的 status 欄位、識別工具的 method 欄位,以及結果資料或失敗時的 reason 欄位。這種一致性意味著 evaluateWorkflowContinuation() 可以對任何工具結果進行統一推理,無論底層硬體類型如何。
fuClaw 提供兩個通訊變體,各自針對不同的部署場景優化。兩者共享相同的 Gemini 推理引擎、工具派送器和持久記憶系統。
Telegram 版本在持久的 WiFiSSLClient 連線上使用 HTTPS 長輪詢對 getUpdates API。主要設計特點:
- 內建身份識別:
chatId作為自然的存取控制層——只有配置的用戶才能發出指令,無需額外的身份驗證層。 - 鍵盤快捷鍵:
telegrambotKeyboard在/help回應中注入持久回覆鍵盤,為常用指令提供手機端一鍵存取。 - HTTP Header 時間寄生:從每次輪詢回應中提取的
Date:header 以零額外成本為 RTC 初始化提供 GMT 時間。 - 語音訊息支援:Telegram 的語音訊息物件(OGG/Opus)被下載、Base64 編碼並內聯發送到 Gemini STT——整個語音到動作的管線無需外部儲存服務。
- 圖像傳遞:相機幀以 multipart JPEG 格式直接上傳到 Telegram 的
sendPhotoAPI,在聊天中傳遞原生照片訊息。 - WorkId 路由:
replyUserMessage()函式使用workId前綴(<BOT>、<PAGE>、<TIME_SCHEDULING>、<THEFT_DETECTION>)將回覆路由到正確的輸出通道,而不需要在整個呼叫堆疊中傳遞通道引用。
MQTT 版本使用具有三個專用主題的 PubSubClient 代理連線:
| 主題 | 方向 | 用途 |
|---|---|---|
xxx/subscribe |
入站 | 接收來自任何 MQTT 客戶端的用戶指令 |
xxx/publish |
出站 | 發送文字回覆 |
xxx/publishimage |
出站 | 發送擷取的 JPEG 幀 |
主要設計特點:
- 隨機客戶端 ID:
"AmebaPro2" + String(random(0xffff), HEX)在每次啟動時生成唯一的客戶端標識符,防止多個設備共用同一代理時發生連線衝突。 - 非阻塞 TCP:
wifiClient.setNonBlockingMode()確保 RTOS 排程器在代理 I/O 期間永遠不會停滯。 - 自動重連:
reconnect()函式以 5 秒重試間隔循環,每次成功重連後重新訂閱指令主題,無需任何手動干預。 - 獨立圖像主題:將 JPEG 資料發布到專用
publishimage主題使二進制圖像有效負載與文字回覆流量乾淨分離,使代理端過濾變得簡單。 - 代理無關性:標準 MQTT 協定意味著韌體與任何代理(Mosquitto、HiveMQ、雲端代理)都能工作,無需程式碼變更——只需更新
env.json。
儘管傳輸層不同,兩個版本共享完全相同的 geminiChatRequest()、geminiSearchRequest()、geminiVisionRequest()、handleAgentResponse()、executeTool()、evaluateWorkflowContinuation()、所有工具處理器以及 SD 卡持久化層的實現。通訊傳輸是唯一的架構差異,使兩個變體的同步維護變得簡單。
一個專屬的 FreeRTOS 任務在埠 81 運行輕量 HTTP 伺服器,提供以下端點:
| 端點 | 功能 |
|---|---|
GET / |
提供 index.html,並預先填入目前憑證 |
GET /updateConfig?{json} |
將 env.json 儲存至 SD 卡並自動重啟 |
GET /agent |
提供 index_agent.html(Agent 設定介面) |
GET /getSoul |
取得 Soul 內容 |
GET /updateSoul?{data} |
使用新內容覆寫 Soul 定義 |
GET /getDevice |
取得 Device 內容 |
GET /updateDevice?{data} |
使用新內容覆寫 Device 定義 |
GET /getSkill |
取得 Skill 內容 |
GET /updateSkill?{data} |
使用新內容覆寫 Skill 定義 |
GET /schedule |
提供 index_schedule.html(排程管理器介面) |
GET /getScheduleTasks |
回傳原始 schedule.json 內容 |
GET /updateScheduleTasks?{json} |
以新任務陣列覆寫 schedule.json |
GET /chat |
提供 index_chat.html(Gemini 網頁聊天介面) |
GET /mqtt |
提供 index_mqtt_chat.html(Gemini 網頁聊天介面) |
GET /message?{text} |
處理聊天訊息並回傳 AI 回覆 |
/updateConfig 端點在寫入 SD 卡前會驗證傳入資料是否為完整 JSON 物件(startsWith("{") && endsWith("}")),防止儲存不完整或損毀的設定。
埠 82 另設第二個伺服器,直接從相機串流 MJPEG 即時影像。
WiFi.enableConcurrent() 同時啟動存取點(192.168.1.1:81)和站台連線。這意味著即使家用 Wi-Fi 不可用,設備也始終可以透過設定介面存取——這對初始設定和現場恢復是一個關鍵功能。
聊天頁面透過 GET /message?<text> 與設備通訊——純 HTTP 查詢,無需 WebSocket 或後端伺服器。設計亮點:
- 自動調整高度的輸入框:輸入欄位隨內容增長,保持行動端視窗整潔。
- 打字指示器:三點彈跳動畫表示 Gemini 正在處理,防止重複提交。
- 內聯圖像渲染:當回應包含
data:image時,氣泡切換到 HTML 渲染模式,直接在聊天中顯示擷取的幀。 - 錯誤提示:網路失敗以計時覆蓋層呈現,而不是破壞 UI 狀態。
- Web 情境的 Markdown 清除:
handleAgentResponse()對<PAGE>workId 應用單獨的清除路徑,將*列表標記轉換為•項目符號並刪除圍欄程式碼塊標記,產生乾淨可讀的輸出,不含原始 Markdown 語法。
MQTT 版聊天介面專為需要持續雙向串流的場景設計,透過 WebSocket 直接連接 MQTT Broker,讓瀏覽器與 fuClaw 之間建立即時的發布/訂閱通道,無需輪詢。設計亮點:
- 側邊欄設定面板:Broker 位址、連接埠、帳號密碼可在執行期填寫,無需修改程式碼;設定區塊支援折疊,保持介面整潔。
- 連線狀態指示器:頂欄的彩色膠囊徽章即時反映連線狀態——綠色呼吸燈(已連線)、琥珀色快閃(連線中)、紅色(斷線),一目了然。
- 動態 Topic 管理:使用者可在執行中新增或移除訂閱主題,並為每個 Topic 獨立指定訊息格式(TEXT / HTML / BASE64 / BIN),連線後即時生效,訂閱清單以標籤色碼區分格式類型。
- 多格式訊息渲染:收到的 Payload 依 Topic 格式設定自動處理——純文字直接顯示、HTML 原生渲染、Base64 與二進位 Buffer 均自動解碼為內聯圖片,攝影機串流畫面可直接呈現於對話氣泡中。
- Topic 標籤標注:每則收到的訊息上方標注來源 Topic 名稱,多主題同時訂閱時訊息來源清晰可辨。
- MQTT 萬用字元支援:Topic 篩選邏輯實作
+單層與#多層萬用字元比對,與標準 MQTT 規範相容。
handleAgentResponse() 在將任何自然語言回應路由到用戶之前,應用系統性的文字標準化。對於 Telegram 輸出,HTML 特殊字元(&、<、>)被轉義以防止注入 Telegram 的 HTML 解析模式。對於 Web 聊天輸出,Markdown 格式化人工產物(**、__、###、```、反引號、---)被清除,* 列表標記被轉換為 • 項目符號。
這種雙路徑淨化確保 Gemini 使用 Markdown 格式的傾向不會將原始語法字元洩漏到 Telegram 聊天或 Web UI 中,無論模型的輸出風格如何。
為了從單一邊緣設備(Standalone Edge Device)演進至**多設備協同運作(Multi-Agent Collaboration)**的物聯網生態系,fuClaw 擴充了其「提示詞編排工具路由機制」(Prompt-Orchestrated Tool Routing),原生新增了三項具備自主通訊能力的邊緣端工具:/agentSendMessage、/agentSendMessageMQTT 與 /agentSendImageMQTT。
這使得 Gemini 推理引擎在評估工作流時,不僅能控制本地端的硬體 GPIO(如指示燈、伺服馬達等),還能自主決定何時透過 P2P 網路或 MQTT 代理伺服器(Broker)向外發送狀態遙測、文字告警或原始二進位多媒體載荷。
| 工具方法 (Method) | 核心職責 (Responsibility) | 限制與安全邊界 (Restrictions & Safety) |
|---|---|---|
/agentSendMessage |
發送直連 P2P 文字訊息至另一台指定的 fuClaw 節點設備。 | 目的端必須在網路可達範圍內,用於輕量級的設備間直接狀態同步。 |
/agentSendMessageMQTT |
透過已連線的 Broker 將文字載荷發布至指定的 MQTT 主題。 | 依賴 env.json 中配置的連線狀態;若與 Broker 斷開會立即回傳 Error JSON。 |
/agentSendImageMQTT |
擷取並將相機當前的視訊快照(Video Snapshot)以二進位發布至特定 MQTT 主題。 | 受 FreeRTOS 棧監視器保護;大圖傳輸會自動啟用動態分塊緩衝優化。 |
-
解耦的多代理人協同 (Decoupled Multi-Agent Collaboration —
/agentSendMessage) 當 Gemini 引擎評估本地感測器數據(例如偵測到 DHT11 溫濕度超越安全臨界值),並判定需要觸發另一個物理區域的連動設備時,會自主調用/agentSendMessage。此設計跳過了中央伺服器的中轉,允許邊緣代理人在應用層直接進行「對話式協同」,且整個決策上下文將完整保留在memory.md中,具備天然的可解釋性。 -
非同步物聯網事件發布 (Asynchronous IoT Pub/Sub —
/agentSendMessageMQTT) 相較於 Telegram 的同步請求-回應(Req-Res)迴圈,/agentSendMessageMQTT提供了亞秒級(Sub-second)的事件廣播能力。訊息能即時發布至env.json指定的mqtt_publishTextTopic主題,這讓 fuClaw 能無縫對接開源智慧家居(如 Home Assistant、Node-RED)或現有的標準物聯網節點(如 ESP32、STM32)。 -
快照複用與記憶體防護 (Frame-Reuse & Memory Shielding —
/agentSendImageMQTT) 在資源極度受限的 FreeRTOS 環境下,透過 MQTT 傳輸數十 KB 的 JPEG 影像極易引發堆疊溢位(Stack Overflow)。為了解決此痛點:- 幀快取複用機制 (Frame Cache Preservation): 補強並繼承了
/still與/vision的核心邏輯。當傳入"frames": false時,工具會直接複用先前視覺任務已鎖定在記憶體中的 JPEG 緩衝區,避免重複觸發相機硬體擷取,大幅節省 CPU 週期。 - 堆積記憶體安全 (Heap Allocation Safety): 傳輸動態影像時,核心採用動態記憶體分配(
malloc/free)而非佔用task_getMqttMessage的執行緒棧(該棧已配置為 32KB),確保 SSL 網路堆疊與 Wi-Fi 吞吐不會因資源爭奪而引發設備當機。
- 幀快取複用機制 (Frame Cache Preservation): 補強並繼承了
每次呼叫 geminiChatRequest() 和 geminiSearchRequest() 都會送出完整的 systemContentTools 提示詞——包含角色定義、所有已確認的裝置映射、硬體安全規則、技能工作流腳本以及完整的工具路由 schema——加上自啟動以來累積的完整對話歷史。在記憶體充裕但 API 預算有限的裝置上,這會產生複利式的後果。
-
每次呼叫的固定開銷。:光是
systemContentTools提示詞本身,在計入使用者訊息或對話歷史之前就可能超過數千個 token。對於一句簡單的問候或事實性問題,這些開銷完全是浪費:不會觸發任何工具、不會碰觸任何裝置,但完整的硬體規則集在每一輪對話中都會通過網路傳送。 -
歷史記錄的膨脹。:
historicalMessages只會累加,不會縮減。每次工具執行都會將其 JSON 結果注入回對話中。一個涉及數次硬體操作、一次視覺分析和一次排程任務評估的工作階段,在單次運行週期內就可能累積數千個 token 的歷史。目前沒有滑動視窗或摘要機制:每次後續呼叫都會逐字送出完整歷史。 -
自主工作流下的成本放大。:
evaluateWorkflowContinuation()在每次工具執行後都會觸發額外的 Gemini 呼叫,以評估工作流是否完成。在多步驟工作流中,一條使用者訊息可能導致四到六次 API 往返,每次都攜帶完整的系統提示詞和不斷增長的歷史記錄。因此,單條使用者訊息的實際 token 帳單,可能是表面估算值的五到十倍。 -
缺乏提示詞分層路由。:程式碼中已存在三個已編譯的系統提示詞(
systemContent、systemContentNoTools、systemContentTools),但主訊息處理器無論使用者的輸入是否與硬體有任何關聯,都固定選用systemContentTools。一個輕量的前置分類呼叫——只使用角色提示詞加上最後幾筆歷史——就能將純聊天輪次路由到systemContent,避免在大多數互動中送出完整的工具 schema。這個優化在架構上直接可行,但尚未實作。
fuClaw 清楚地證明了一件事:完整的 AI Agent 不需要雲端伺服器。
在一塊沒有作業系統、記憶體以 KB 計算的嵌入式開發板上,fuClaw 實現了完整的 Agent Loop——感知、推理、工具執行、記憶體持久化——全部在板端完成,延遲由網路決定,而非運算能力。
核心架構突破在於以 Prompt Engineering 取代 Native Function Calling:透過嚴格的 JSON schema 約束 LLM 輸出,再由韌體層驗證並執行,不依賴任何特定 LLM 廠商的 API 擴充,使整個推理引擎具備高度可移植性。
fuClaw 是一個可運行的參考實作,而非經過生產優化的成品。 它的設計目標是展示嵌入式硬體在架構層面的可能性,並提供一個完整、可直接執行的起點,而不是一張白紙。雙模式範例程式碼(Telegram 與 MQTT)端對端涵蓋了完整的 Agent Loop,適配新場景只需修改 soul.md 與 device.md,核心架構無需重新設計。
然而,若要在成本敏感或高頻率使用的環境中部署 fuClaw,需要審慎評估第 15 節所描述的 token 用量問題。目前每次互動都會將完整的系統提示詞與完整的對話歷史送至 Gemini API。對於偶發的個人使用或低流量原型,這個成本微不足道。但對於每天處理數十次互動、長期運行數個月的裝置,或是任何已超出 Gemini API 免費額度的部署場景,累積的 token 消耗在正式上線前都值得仔細評估。
如果你正在評估以 fuClaw 作為更大型專案的基礎,請將第 14 節視為擴展規模前需要逐一確認的檢查清單。架構本身是穩健的;成本結構只需與你的使用模式相匹配。